阅读笔记主要来自原书第 6 章。该章对操作系统如何有效且高效地运行进程进行了系统性的介绍,可以帮助读者更好地了解进程的运行机制。
0、前言
为了虚拟化 CPU,操作系统需要以某种方式让许多任务共享物理 CPU,让它们看起来像是同时运行。基本思想很简单:运行一个进程一段时间,然后运行另一个进程,如此轮换。通过以这种方式时分共享 CPU,就实现了虚拟化。
然而,在构建这样的虚拟化机制时存在一些挑战。第一个是性能:如何在不增加系统开销的情况下实现虚拟化?第二个是控制权:如何有效地运行进程,同时保留对CPU的控制?控制权对于操作系统尤为重要,因为操作系统负责资源管理。如果没有控制权,一个进程可以简单地无限制运行并接管机器,或访问没有权限的信息。因此,在保持控制权的同时获得高性能,这是构建操作系统的主要挑战之一。
操作系统必须以高性能的方式虚拟化CPU,同时保持对系统的控制。为此,需要硬件和操作系统支持。操作系统通常会明智地利用硬件支持,以便高效地实现其工作。
1、基本技巧:受限直接执行
为了使程序尽可能快地运行,操作系统开发人员想出了一种技术——受限的直接执行(limited direct execution)。这个概念的“直接执行”部分很简单:只需直接在 CPU 上运行程序即可。因此,当操作系统希望启动程序运行时,它会在进程列表中为其创建一个进程条目,为其分配一些内存,将程序代码从磁盘加载到内存中,找到入口点(main() 函数),跳转到那里,并开始运行用户的代码。下表展示了这种基本的直接执行协议(没有任何限制),使用正常的调用并返回跳转到程序的 main(),并在稍后回到内核。

看上去很简单,但是,这种方法在我们的虚拟化 CPU 时产生了一些问题。第一个问题很简单:如果我们只运行一个程序,操作系统怎么能确保程序不做任何我们不希望它做的事,同时仍然高效地运行它?第二个问题:当我们运行一个进程时,操作系统如何让它停下来并切换到另一个进程,从而实现虚拟化 CPU 所需的时分共享?
2、问题 1:受限制的操作
直接执行的明显优势是快速。该程序直接在硬件 CPU 上运行,因此执行速度与预期的一样快。但是,在 CPU 上运行会带来一个问题——如果进程希望执行某种受限操作(如向磁盘发出 I/O 请求或获得更多系统资源(如CPU或内存)),该怎么办?
关键问题:如何执行受限制的操作?
一个进程必须能够执行 I/O 和其他一些受限制的操作,但又不能让进程完全控制系统。操作系统和硬件如何协作实现这一点?
提示:采用受保护的控制权转移
硬件通过提供不同的执行模式来协助操作系统。在用户模式(user mode)下,应用程序不能完全访问硬件资源。在内核模式(kernel mode)下,操作系统可以访问机器的全部资源。还提供了陷入(trap)内核和从陷阱返回(return-from-trap)到用户模式程序的特别说明,以及一些指令,让操作系统告诉硬件陷阱表(trap table)在内存中的位置。
对于 I/O 和其他相关操作,一种方法就是让所有进程做所有它想做的事情。但是,这样做导致无法构建许多我们想要的系统。例如,如果我们希望构建一个在授予文件访问权限前检查权限的文件系统,就不能简单地让任何用户进程向磁盘发出 I/O。如果这样做,一个进程就可以读取或写入整个磁盘,这样所有的保护都会失效。
因此,我们采用的方法是引入一种新的处理器模式,称为用户模式。在用户模式下运行的代码会受到限制。例如,在用户模式下运行时,进程不能发出 I/O 请求。这样做会导致处理器引发异常,操作系统可能会终止进程。
与用户模式不同的内核模式,操作系统(或内核)就以这种模式运行。在此模式下,运行的代码可以做它喜欢的事,包括特权操作,如发出 I/O 请求和执行所有类型的受限指令。但是,还面临着一个挑战——如果用户希望执行某种特权操作(如从磁盘读取),应该怎么做?为了实现这一点,几乎所有的现代硬件都提供了用户程序执行系统调用的能力。系统调用是在 Atlas 等古老机器上开创的,它允许内核小心地向用户程序暴露某些关键功能,例如访问文件系统、创建和销毁进程、与其他进程通信,以及分配更多内存。大多数操作系统提供几百个调用(详见POSIX标准)。早期的UNIX系统公开了更简洁的子集,大约 20 个调用。
要执行系统调用,程序必须执行特殊的 trap 指令。该指令跳入内核并将特权级别提升到内核模式。一旦进入内核,系统就可以执行任何需要的特权操作(如果允许),从而为调用进程执行所需的工作。完成后,操作系统调用一个特殊的从 tarp 返回指令,该指令返回到发起调用的用户程序中,同时将特权级别降低,回到用户模式。
执行陷阱时,硬件需要小心,因为它必须确保存储足够的调用者寄存器,以便在操作系统发出从陷阱返回指令时能够正确返回。例如,在x86上,处理器会将程序计数器、标志和其他一些寄存器推送到每个进程的内核栈上。从 tarp 返回时将从栈弹出这些值,并恢复执行用户模式程序。其他硬件系统使用不同的约定,但基本概念在各个平台上是相似的。
补充:为什么系统调用看起来像过程调用
你可能想知道,为什么对系统调用的调用(如 open() 或 read())看起来完全就像 C 中的典型过程调用。也就是说,如果它看起来像一个过程调用,系统如何知道这是一个系统调用,并做所有正确的事情?
原因很简单:它是一个过程调用,但隐藏在过程调用内部的是著名的 trap 指令。更具体地说,当调用 open() 时,正在执行对 C 库的过程调用。其中,无论是对于 open() 还是提供的其他系统调用,库都使用与内核一致的调用约定来将参数放在众所周知的位置(例如,在栈中或特定的寄存器中),将系统调用号也放入一个众所周知的位置(同样,放在栈或寄存器中),然后执行上述的 trap 指令。库中 trap 之后的代码准备好返回值,并将控制权返回给发出系统调用的程序。
因此,C 库中进行系统调用的部分是用汇编手工编码的,因为它们需要仔细遵循约定,以便正确处理参数和返回值,以及执行硬件特定的陷阱指令。
还有一个重要的细节没讨论:trap 如何知道在操作系统内运行哪些代码?显然,发起调用的过程不能指定要跳转到的地址,这样做让程序可以跳转到内核中的任意位置,这显然是一个糟糕的主意(想象一下跳到访问文件的代码,但在权限检查之后。实际上,这种能力很可能让一个狡猾的程序员令内核运行任意代码序列)。因此内核必须谨慎地控制在陷阱上执行的代码。
内核通过在启动时设置 trap table 来实现。当机器启动时,它在特权(内核)模式下执行,因此可以根据需要自由配置机器硬件。操作系统做的第一件事,就是告诉硬件在发生某些异常事件时要运行哪些代码。例如,当发生硬盘中断,发生键盘中断或程序进行系统调用时,应该运行哪些代码?操作系统通常通过某种特殊的指令,通知硬件这些陷阱处理程序的位置。一旦硬件被通知,它就会记住这些处理程序的位置,直到下一次重新启动机器,并且硬件知道在发生系统调用和其他异常事件时要做什么(即跳转到哪段代码)。
最后再插一句:能够执行指令来告诉硬件 trap table 的位置是一个非常强大的功能。因此,这也是一项特权操作。如果试图在用户模式下执行这个指令,硬件不会允许。
下标总结了该协议。假设每个进程都有一个内核栈,在进入内核和离开内核时,寄存器(包括通用寄存器和程序计数器)分别被保存和恢复。
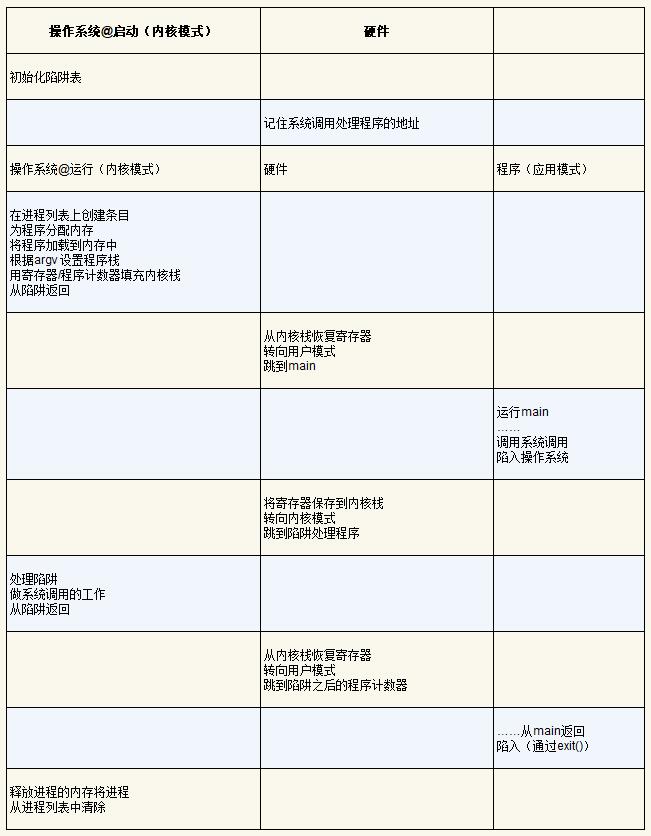
受限直接执行协议包含两个阶段。
- 第一个阶段(在系统引导时),内核初始化 trap table,并且 CPU 记住它的位置以供随后使用。内核通过特权指令来执行此操作(所有特权指令均以粗体突出显示)。
- 第二个阶段(运行进程时),在从 trap 返回指令开始执行进程之前,内核设置了一些内容(例如,在进程列表中分配一个节点,分配内存)。然后将 CPU 切换到用户模式并开始运行该进程。
- 当进程希望发出系统调用时,它会重新陷入操作系统,然后再次通过从 trap 返回,将控制权还给进程。该进程然后完成它的工作,并从 main() 返回。这通常会返回到一些 stub 代码,它将正确退出该程序(例如,通过调用 exit() 系统调用,这将陷入操作系统中)。此时,操作系统清理干净,任务完成了。
3、问题 2:在进程间切换
直接执行的下一个问题是实现进程之间的切换。在进程之间切换看上去很简单,操作系统应该决定停止一个进程并开始另一个进程。但实际上这有点棘手,特别是,如果一个进程在 CPU 上运行,这就意味着操作系统没有运行。如果操作系统没有运行,它怎么能做事情?(提示:它不能)虽然这听起来几乎是哲学,但这是真正的问题——如果操作系统没有在CPU上运行,那么操作系统显然没有办法采取行动。因此,我们遇到了关键问题。
3.1、协作方式:等待系统调用
过去某些系统采用的一种方式(例如,早期版本的 Macintosh 操作系统)称为协作方式。在这种风格下,操作系统相信系统的进程会合理运行。运行时间过长的进程被假定会定期放弃 CPU,以便操作系统可以决定运行其他任务。
在这个虚拟的世界中,一个友好的进程如何放弃 CPU?事实证明,大多数进程通过进行系统调用,将CPU 的控制权转移给操作系统,例如打开文件并随后读取文件,或者向另一台机器发送消息或创建新进程。像这样的系统通常包括一个显式的 yield 系统调用,它什么都不干,只是将控制权交给操作系统,以便系统可以运行其他进程。
操作系统通常必须处理不当行为,这些程序通过设计(恶意)或不小心(错误),尝试做某些不应该做的事情。在现代系统中,操作系统试图处理这种不当行为的方式是简单地终止犯罪者。一击出局!
如果应用程序执行了某些非法操作,也会将控制转移给操作系统。例如,如果应用程序以0为除数,或者尝试访问应该无法访问的内存,就会陷入操作系统。操作系统将再次控制 CPU(并可能终止违规进程)。
因此,在协作调度系统中,操作系统通过等待系统调用,或某种非法操作发生,从而重新获得 CPU 的控制权。但这种被动方式过于理想。例如,如果某个进程(无论是恶意的还是充满缺陷的)进入无限循环,并且从不进行系统调用,会发生什么情况?那时操作系统能做什么?
3.2、非协作方式:操作系统进行控制
事实证明,没有硬件的额外帮助,如果进程拒绝进行系统调用(也不出错),从而将控制权交还给操作系统,那么操作系统无法做任何事情。事实上,在协作方式中,当进程陷入无限循环时,唯一的办法就是使用古老的解决方案来解决计算机系统中的所有问题——重新启动计算机。因此,我们又遇到了请求获得 CPU 控制权的一个子问题。
即使进程不协作,操作系统如何获得 CPU 的控制权?操作系统可以做什么来确保流氓进程不会占用机器?
答案很简单,许多年前构建计算机系统的许多人都发现了:时钟中断(timer interrupt)。时钟设备可以编程为每隔几毫秒产生一次中断。产生中断时,当前正在运行的进程停止,操作系统中预先配置的中断处理程序(interrupt handler)会运行。此时,操作系统重新获得CPU的控制权,因此可以做它想做的事:停止当前进程,并启动另一个进程。
即使进程以非协作的方式运行,添加时钟中断也让操作系统能够在 CPU 上重新运行。因此,该硬件功能对于帮助操作系统维持机器的控制权至关重要。
首先,正如之前讨论过的系统调用一样,操作系统必须通知硬件哪些代码在发生时钟中断时运行。因此,在启动时,操作系统就是这样做的。其次,在启动过程中,操作系统也必须启动时钟,这当然是一项特权操作。一旦时钟开始运行,操作系统就感到安全了,因为控制权最终会归还给它,因此操作系统可以自由运行用户程序。
请注意,硬件在发生中断时有一定的责任,尤其是在中断发生时,要为正在运行的程序保存足够的状态,以便随后从陷阱返回指令能够正确恢复正在运行的程序。这一组操作与硬件在显式系统调用陷入内核时的行为非常相似,其中各种寄存器因此被保存(进入内核栈),因此从陷阱返回指令可以容易地恢复。
3.3、保存和恢复上下文
既然操作系统已经重新获得了控制权,无论是通过系统调用协作,还是通过时钟中断更强制执行,都必须决定:是继续运行当前正在运行的进程,还是切换到另一个进程。这个决定是由调度程序做出的,它是操作系统的一部分。在接下来的主题中会详细讨论调度策略。
如果决定进行切换,操作系统就会执行一些底层代码,即所谓的上下文切换。上下文切换在概念上很简单:操作系统要做的就是为当前正在执行的进程保存一些寄存器的值(例如,到它的内核栈),并为即将执行的进程恢复一些寄存器的值(从它的内核栈)。这样一来,操作系统就可以确保最后执行从陷阱返回指令时,不是返回到之前运行的进程,而是继续执行另一个进程。
为了保存当前正在运行的进程的上下文,操作系统会执行一些底层汇编代码,来保存通用寄存器、程序计数器,以及当前正在运行的进程的内核栈指针,然后恢复寄存器、程序计数器,并切换内核栈,供即将运行的进程使用。通过切换栈,内核在进入切换代码调用时,是一个进程(被中断的进程)的上下文,在返回时,是另一进程(即将执行的进程)的上下文。当操作系统最终执行从陷阱返回指令时,即将执行的进程变成了当前运行的进程。至此上下文切换完成。
下表展示了整个过程的时间线。在这个例子中,进程 A 正在运行,然后被中断时钟中断。硬件保存它的寄存器(到内核栈中),并进入内核(切换到内核模式)。在时钟中断处理程序中,操作系统决定从正在运行的进程 A 切换到进程 B。此时,它调用 switch() 程序,该程序仔细保存当前寄存器的值(保存到 A 的进程结构中),恢复进程 B 的寄存器(从它的进程结构中),然后切换上下文,具体来说是通过改变栈指针来使用 B 的内核栈(而不是 A 的)。最后,操作系统从 trap 返回,恢复 B 的寄存器并开始运行它。

请注意,在此协议中,有两种类型的寄存器保存/恢复。第一种是发生时钟中断的时候。在这种情况下,运行进程的用户寄存器由硬件隐式保存,使用该进程的内核栈。第二种是当操作系统决定从 A 切换到 B。在这种情况下,内核寄存器被软件(即操作系统)明确地保存,但这次被存储在该进程的进程结构的内存中。后一个操作让系统从好像刚刚由 A 陷入内核,变成好像刚刚由 B 陷入内核。
What's the difference between user registers and kernel registers?
It's simple - when each application program runs, it has access to its own set of registers. When you switch to other application, these register contents is saved to memory, and registers, saved from other application, loaded and this application continues its execution.
Similarly, OS has its own register contents. Depending on CPU, it may even has its own, different register set. Moreover, some CPUs has two physical register sets - for apps and for OS, thus allowing fast switching from app to OS and back again (f.e. when app requests some service from OS).
Now let's look at your citation. I'm not an OS specialist, but this text means that for each application, we have specific contents of OS registers. F.e. these registers may hold app-specific data which isn't available to app itself (such as security context of the app). So, when you switch from app to OS (usually by requesting some OS service), OS registers are immediately ready to use, making the call faster. OTOH, when you switch to other app, the entire set of kernel registers need to be saved and kernel registers for other app should be loaded instead.
Since task switching is much less frequent operation, this makes the entire execution faster.
为了更好地了解如何实现这种切换,下面给出了 xv6 的上下文切换代码。context 结构 old 和 new 分别在老的和新的进程的进程结构中。
# void swtch(struct context **old, struct context *new);
#
# Save current register context in old
# and then load register context from new.
.globl switch
switch:
# Save old registers
movl 4(%esp), %eax # put old ptr into eax
popl 0(%eax) # save the old IP
movl %esp, 4(%eax) # and stack
movl %ebx, 8(%eax) # and other registers
movl %ecx, 12(%eax)
movl %edx, 16(%eax)
movl %esi, 20(%eax)
movl %edi, 24(%eax)
movl %ebp, 28(%eax)
# Load new registers
movl 4(%esp), %eax # put new ptr into eax
movl 28(%eax), %ebp # restore other registers
movl 24(%eax), %edi
movl 20(%eax), %esi
movl 16(%eax), %edx
movl 12(%eax), %ecx
movl 8(%eax), %ebx
movl 4(%eax), %esp # stack is switched here
pushl 0(%eax) # return addr put in place
ret # finally return into new ctxt
4、并发问题
“呃……在系统调用期间发生时钟中断时会发生什么?”或“处理一个中断时发生另一个中断,会发生什么?这不会让内核难以处理吗?”
答案是肯定的,如果在中断或陷阱处理过程中发生另一个中断,那么操作系统确实需要关心发生了什么。
操作系统可能简单地决定,在中断处理期间禁止中断。这样做可以确保在处理一个中断时,不会将其他中断交给CPU。当然,操作系统这样做必须小心。禁用中断时间过长可能导致丢失中断,这是不好的。
操作系统还开发了许多复杂的加锁方案,以保护对内部数据结构的并发访问。这使得多个活动可以同时在内核中进行,特别适用于多处理器。
补充:上下文切换要多长时间?
一个很自然的问题:上下文切换需要多长时间?甚至系统调用要多长时间?如果感到好奇,有一种称为 lmbench 的工具,可以准确衡量这些事情,并提供其他一些可能相关的性能指标。
随着时间的推移,结果有了很大的提高,大致跟上了处理器的性能提高。例如,1996 年在 200-MHz P6 CPU上运行 Linux 1.3.37,系统调用花费了大约 4μs,上下文切换时间大约为 6μs。
现代系统的性能几乎可以提高一个数量级,在具有 2 GHz或 3 GHz处理器的系统上的性能可以达到亚微秒级。
5、小节
本章介绍了一些实现 CPU 虚拟化的关键底层机制,并将其统称为受限直接执行。基本思路很简单:就让想运行的程序在 CPU 上运行,但首先确保设置好硬件,以便在没有操作系统帮助的情况下限制进程可以执行的操作。
这种一般方法也在现实生活中采用。例如,那些有孩子或至少听说过孩子的人可能会熟悉宝宝防护房间的概念——锁好包含危险物品的柜子,并掩盖电源插座。当这些都准备妥当时,你可以让宝宝自由行动,确保房间最危险的方面受到限制。
通过类似的方式,操作系统首先(在启动时)设置陷阱处理程序并启动时钟中断,然后仅在受限模式下运行进程,以此为CPU提供“宝宝防护”。这样做,操作系统能确信进程可以高效运行,只在执行特权操作,或者当它们独占 CPU 时间过长并因此需要切换时,才需要操作系统干预。
至此,我们有了虚拟化CPU的基本机制。但一个主要问题还没有答案:在特定时间,我们应该运行哪个进程?调度程序必须回答这个问题,因此这也是需要研究的下一个主题。
提示:重新启动是有用的:)
之前提到,在协作式抢占时,无限循环(以及类似行为)的唯一解决方案是重启机器。虽然这种做法很粗暴,但研究表明,重启(或在通常意义上说,重新开始运行一些软件)可能是构建强大系统的一个非常有用的工具。
具体来说,重新启动很有用,因为它让软件回到已知的状态,很可能是经过更多测试的状态。重新启动还可以回收旧的或泄露的资源(例如内存),否则这些资源可能很难处理。最后,重启很容易自动化。由于所有这些原因,在大规模集群互联网服务中,系统管理软件定期重启一些机器,重置它们并因此获得以上好处,这并不少见。


