阅读笔记主要来自原书第 4 章。该章对进程的概念、创建、状态等进行了系统性的介绍,可以帮助读者更好地了解进程背后的原理。
0、前言
进程的非正式定义非常简单:进程就是运行中的程序。程序本身是没有生命周期的,它只是存在磁盘上面的一些指令(也可能是一些静态数据)。是操作系统让这些字节运行起来,让程序发挥作用。
事实表明,人们常常希望同时运行多个程序。比如:在使用计算机或者笔记本的时候,我们会同时运行浏览器、邮件、游戏、音乐播放器,等等。实际上,一个正常的系统可能会有上百个进程同时在运行。如果能实现这样的系统,人们就不需要考虑这个时候哪一个CPU是可用的,使用起来非常简单。
那么问题来了:虽然只有少量的物理 CPU 可用,但是操作系统如何提供几乎有无数个 CPU 可用的假象?
操作系统通过虚拟化 CPU 来提供这种假象。通过让一个进程只运行一个时间片,然后切换到其他进程,操作系统提供了存在多个虚拟 CPU 的假象。这就是时分共享 CPU 技术,允许用户如愿运行多个并发进程。潜在的开销就是性能损失,因为如果 CPU 必须共享,每个进程的运行就会慢一点。
要实现 CPU 的虚拟化,而且想要实现得好,操作系统就需要一些低级机制以及一些高级智能。我们将低级机制称为机制(mechanism)。机制是一些低级方法或协议,实现了所需的功能。例如,我们稍后将学习如何实现上下文切换(context switch),它让操作系统能够停止运行一个程序,并开始在给定的 CPU 上运行另一个程序。所有现代操作系统都采用了这种分时机制。
时分共享是操作系统共享资源所使用的最基本的技术之一。通过允许资源由一个实体使用一小段时间,然后由另一个实体使用一小段时间,如此下去,所谓的资源(例如 CPU)可以被许多人共享。时分共享的自然对应技术是空分共享,资源在空间上被划分给希望使用它的人。例如,磁盘空间自然是一个空分共享资源,因为一旦将块分配给文件,在用户删除文件之前,不可能将它分配给其他文件。
在这些机制之上,操作系统中有一些智能以策略的形式存在。策略是在操作系统内做出某种决定的算法。例如,给定一组可能的程序要在 CPU 上运行,操作系统应该运行哪个程序?操作系统中的调度策略会做出这样的决定,可能利用历史信息(例如,哪个程序在最后一分钟运行得更多?)、工作负载知识(例如,运行什么类型的程序?)以及性能指标 (例如,系统是否针对交互式性能或吞吐量进行优化?)来做出决定。
1、抽象:进程概念
操作系统为正在运行的程序提供的抽象,就是所谓的进程。正如上面所说的,一个进程只是一个正在运行的程序。在任何时刻,都可以清点它在执行过程中访问或影响的系统的不同部分,从而概括一个进程。
为了理解构成进程的是什么,我们必须理解它的机器状态:程序在运行时可以读取或更新的内容。在任何时刻,机器的哪些部分对执行该程序很重要?
进程的机器状态有一个明显组成部分,就是它的内存。指令存在内存中。正在运行的程序读取和写入的数据也在内存中。因此进程可以访问的内存(称为地址空间,address space)是该进程的一部分。
进程的机器状态的另一部分是寄存器。许多指令明确地读取或更新寄存器,因此显然,它们对于执行该进程很重要。请注意,有一些非常特殊的寄存器构成了该机器状态的一部分。例如,程序计数器(Program Counter,PC)告诉我们程序当前正在执行哪个指令;类似地,栈指针(stack pointer)和相关的帧指针(frame pointer)用于管理函数参数栈、局部变量和返回地址。
最后,程序也经常访问持久存储设备。此类 I/O 信息可能包含当前打开的文件列表。
2、进程创建:更多细节
程序如何转化为进程。具体来说,操作系统如何启动并运行一个程序?进程创建实际如何进行?
操作系统运行程序必须做的第一件事是将代码和所有静态数据(例如初始化变量)加载到内存中,加载到进程的地址空间中。程序最初以某种可执行格式驻留在磁盘上。因此,将程序和静态数据加载到内存中的过程,需要操作系统从磁盘读取这些字节,并将它们放在内存中的某处。
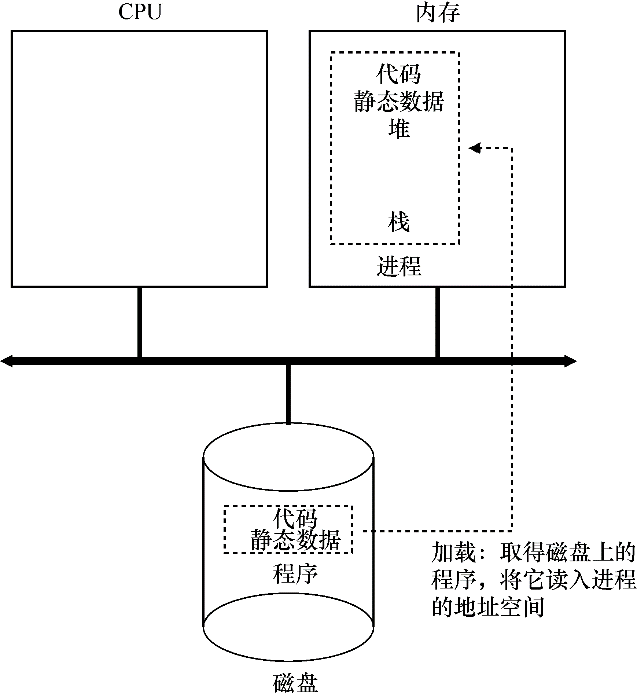
在早期的(或简单的)操作系统中,加载过程尽早(eagerly)完成,即在运行程序之前全部完成。现代操作系统惰性(lazily)执行该过程,即仅在程序执行期间需要加载的代码或数据片段,才会加载。要真正理解代码和数据的惰性加载是如何工作的,必须更多地了解分页和交换的机制,这是将来讨论内存虚拟化时要涉及的主题。现在,只要记住在运行任何程序之前,操作系统显然必须做一些工作,才能将重要的程序字节从磁盘读入内存。
为什么我们要以 eager 的方式将程序加载到内存中?为什么不再等等,直到应用程序实际需要这些指令的时候再加载内存?程序的二进制文件可能非常的巨大,将它全部从磁盘加载到内存中将会是一个代价很高的操作。又或者 data 区域的大小远大于常见的场景所需要的大小,我们并不一定需要将整个二进制都加载到内存中。
所以对于 exec,在虚拟地址空间中,我们为 text 和 data 分配好地址段,但是相应的 PTE 并不对应任何物理内存 page。对于这些 PTE,我们只需要将 valid bit 位设置为 0 即可。
那么该如何处理这里的 page fault 呢?首先我们可以发现,这些 page 是on-demand page。我们需要在某个地方记录了这些 page 对应的程序文件,我们在 page fault handler 中需要从程序文件中读取 page 数据,加载到内存中;之后将内存 page 映射到 page table,最后再重新执行指令。
之后程序就可以运行了。在最坏的情况下,用户程序使用了 text 和 data 中的所有内容,那么我们将会在应用程序的每个 page 都收到一个 page fault。但是如果我们幸运的话,用户程序并没有使用所有的 text 区域或者 data 区域,那么我们一方面可以节省一些物理内存,另一方面我们可以让exec 运行的更快(因为不需要为整个程序分配内存)。
——《MIT6.S081》Lec8.5 Demand Paging
将代码和静态数据加载到内存后,操作系统在运行此进程之前还需要执行其他一些操作。必须为程序的运行时栈(run-time stack 或 stack)分配一些内存。C 程序使用栈存放局部变量、函数参数和返回地址。操作系统分配这些内存,并提供给进程。操作系统也可能会用参数初始化栈。具体来说,它会将参数填入 main() 函数,即 argc 和 argv 数组。
操作系统也可能为程序的堆(heap)分配一些内存。在 C 程序中,堆用于显式请求的动态分配数据。程序通过调用 malloc() 来请求这样的空间,并通过调用 free() 来明确地释放它。数据结构(如链表、散列表、树和其他有趣的数据结构)需要堆。起初堆会很小。随着程序运行,通过 malloc() 库API请求更多内存,操作系统可能会参与分配更多内存给进程,以满足这些调用。
操作系统还将执行一些其他初始化任务,特别是与输入/输出(I/O)相关的任务。例如,在 UNIX 系统中,默认情况下每个进程都有3个打开的文件描述符(file descriptor),用于标准输入、输出和错误。这些描述符让程序轻松读取来自终端的输入以及打印输出到屏幕。
通过将代码和静态数据加载到内存中,通过创建和初始化栈以及执行与 I/O 设置相关的其他工作,操作系统为程序执行搭好了舞台。然后它有最后一项任务:启动程序,在入口处运行,即 main()。通过跳转到 main() 函数,操作系统将 CPU 的控制权转移到新创建的进程中,从而程序开始执行。
3、进程状态
既然已经了解了进程是什么,以及大致上它是如何创建的,接下来谈谈进程在给定时间可能处于的不同状态(state)。在早期的计算机系统中,出现了一个进程可能处于这些状态之一的概念。简而言之,进程可以处于以下3种状态之一。
- 运行(running):在运行状态下,进程正在处理器上运行。这意味着它正在执行指令。
- 就绪(ready):在就绪状态下,进程已准备好运行,但由于某种原因,操作系统选择不在此时运行。
- 阻塞(blocked):在阻塞状态下,一个进程执行了某种操作,直到发生其他事件时才会准备运行。一个常见的例子是,当进程向磁盘发起 I/O 请求时,它会被阻塞,因此其他进程可以使用处理器。
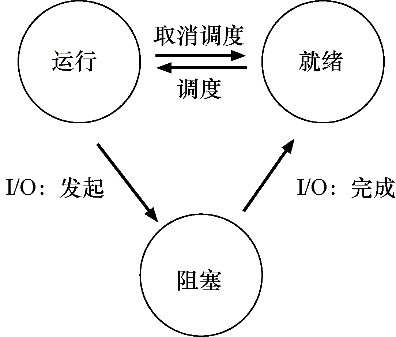
如图所示,可以根据操作系统的判断,让进程在就绪状态和运行状态之间转换。从就绪到运行意味着该进程已经被调度。从运行转移到就绪意味着该进程已经取消调度。一旦进程被阻塞(例如,通过发起 I/O 操作),操作系统将保持进程的这种状态,直到发生某种事件(例如,I/O 完成)。此时,进程再次转入就绪状态(也可能立即再次运行,如果操作系统这样决定)。
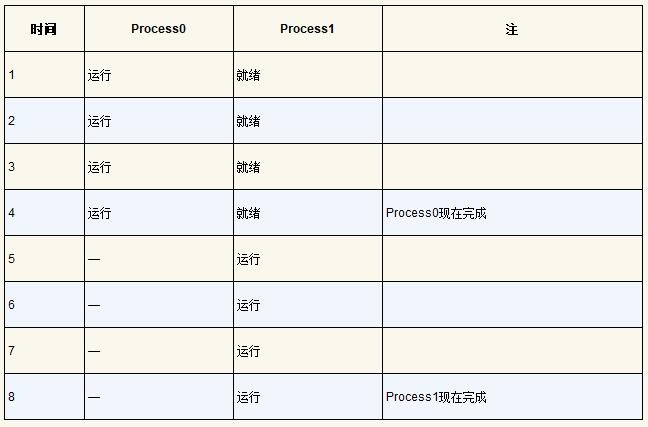
举个例子,来看两个进程如何通过这些状态转换。首先,想象两个正在运行的进程,每个进程只使用CPU(它们没有 I/O)。在这种情况下,每个进程的状态可能如表所示。
在下一个例子中,第一个进程在运行一段时间后发起I/O请求。此时,该进程被阻塞,让另一个进程有机会运行。下表展示了这种场景。
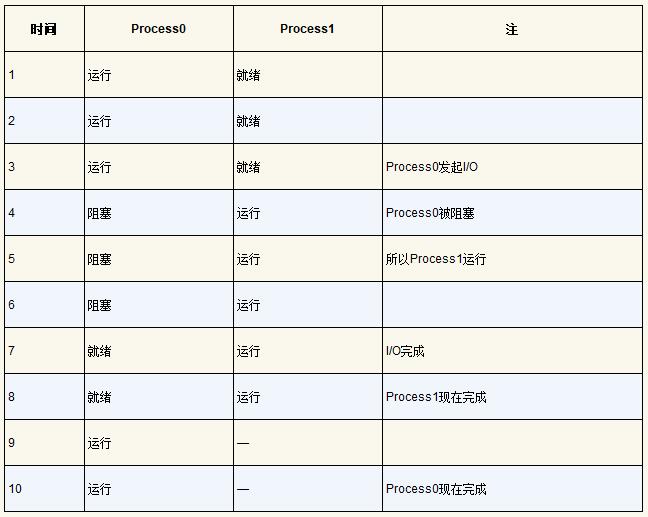
更具体地说,Process0 发起 I/O 并被阻塞,等待 I/O 完成。例如,当从磁盘读取数据或等待网络数据包时,进程会被阻塞。操作系统发现 Process0 不使用 CPU 并开始运行 Process1。当 Process1 运行时,I/O 完成,将 Process0 移回就绪状态。最后,Process1 结束,Process0 运行,然后完成。
请注意,即使在这个简单的例子中,操作系统也必须做出许多决定。首先,系统必须决定在 Process0 发出 I/O 时运行 Process1。这样做可以通过保持 CPU 繁忙来提高资源利用率。其次,当 I/O 完成时,系统决定不切换回 Process0。目前还不清楚这是不是一个很好的决定。你怎么看?这些类型的决策由操作系统调度程序完成,这是在后面要讨论的主题。
4、数据结构
操作系统是一个程序,和其他程序一样,它有一些关键的数据结构来跟踪各种相关的信息。例如,为了跟踪每个进程的状态,操作系统可能会为所有就绪的进程保留某种进程列表,以及跟踪当前正在运行的进程的一些附加信息。操作系统还必须以某种方式跟踪被阻塞的进程。当 I/O 事件完成时,操作系统应确保唤醒正确的进程,让它准备好再次运行。
有时候人们会将存储关于进程的信息的个体结构称为进程控制块(Process Control Block,PCB),这是谈论包含每个进程信息的C结构的一种方式。
在 Linux 系统中,对应的数据结构为 task_struct。
下面的代码展示了操作系统需要跟踪 xv6 内核中每个进程的信息类型。“真正的”操作系统中存在类似的进程结构,如 Linux、macOS X 或 Windows。
// the registers xv6 will save and restore
// to stop and subsequently restart a process
struct context {
int eip;
int esp;
int ebx;
int ecx;
int edx;
int esi;
int edi;
int ebp;
};
// the different states a process can be in
enum proc_state { UNUSED, EMBRYO, SLEEPING,
RUNNABLE, RUNNING, ZOMBIE };
// the information xv6 tracks about each process
// including its register context and state
struct proc {
char *mem; // Start of process memory
uint sz; // Size of process memory
char *kstack; // Bottom of kernel stack
// for this process
enum proc_state state; // Process state
int pid; // Process ID
struct proc *parent; // Parent process
void *chan; // If non-zero, sleeping on chan
int killed; // If non-zero, have been killed
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
struct context context; // Switch here to run process
struct trapframe *tf; // Trap frame for the
// current interrupt
};
从上述代码中可以看到,操作系统追踪进程的一些重要信息。对于停止的进程,寄存器上下文将保存其寄存器的内容。当一个进程停止时,它的寄存器将被保存到这个内存位置。通过恢复这些寄存器(将它们的值放回实际的物理寄存器中),操作系统可以恢复运行该进程。在后面的主题中会更多地了解这种技术,它被称为上下文切换。
还可以看到,除了运行、就绪和阻塞之外,还有其他一些进程可以处于的状态。有时候系统会有一个初始状态,表示进程在创建时处于的状态。另外,一个进程可以处于已退出但尚未清理的最终状态(在基于 UNIX 的系统中,这称为僵尸状态)。这个最终状态非常有用,因为它允许其他进程(通常是创建进程的父进程)检查进程的返回代码,并查看刚刚完成的进程是否成功执行(通常,在基于 UNIX 的系统中,程序成功完成任务时返回零,否则返回非零)。完成后,父进程将进行最后一次调用(例如,wait()),以等待子进程的完成,并告诉操作系统它可以清理这个正在结束的进程的所有相关数据结构。
5、小结
本章介绍了操作系统的最基本抽象:进程。它很简单地被视为一个正在运行的程序。有了这个概念,接下来将继续讨论具体细节:实现进程所需的低级机制和以智能方式调度这些进程所需的高级策略。结合机制和策略,可以加深对操作系统如何虚拟化 CPU 的理解。


