阅读笔记主要来自原书第 7 章。该章对进程的调度策略等进行了系统性的介绍,可以帮助读者更好地了解进程调度策略的发展过程。
现在,运行进程的底层机制(如上下文切换)应该清楚了。然而,操作系统调度程序采用的上层策略还不明了。接下来会介绍一系列的调度策略(sheduling policy),它们是许多聪明又努力的人在过去这些年里开发的。
关键问题为:如何开发一个考虑调度策略的基本框架?什么是关键假设?哪些指标非常重要?哪些基本方法已经在早期的系统中使用?
1、工作负载假设
探讨可能的策略范围之前,先做一些简化的假设。这些假设与系统中运行的进程有关,有时候统称为工作负载。确定工作负载是构建调度策略的关键部分。工作负载了解得越多,策略就可能越优化。
目前这里做的工作负载的假设是不切实际的,但这没问题,因为后面会放宽这些假定,并最终开发出一个完全可操作的调度准则。
对操作系统中运行的进程(有时也叫工作任务)做出如下的假设:
- 每一个工作运行相同的时间。
- 所有的工作同时到达。
- 一旦开始,每个工作保持运行直到完成。
- 所有的工作只是使用 CPU(即它们不执行 IO 操作)。
- 每个工作的运行时间是已知的。
2、调度指标
除了做出工作负载假设之外,还需要调度指标用于比较不同的调度策略。
现在,简化一下,只用一个指标:周转时间(turnaround time)。任务的周转时间定义为任务完成时间减去任务到达系统的时间。即
T_{周转时间} = T_{完成时间} - T_{到达时间}
因为假设所有的任务在同一时间到达,那么 T_{到达时间} = 0,因此 T_{周转时间} = T_{完成时间}。随着上述假设的放宽,这个情况也会有所改变。
周转时间是一个性能(performance)指标,这将是本章的首要关注点。另一个有趣的指标是公平(fairness),比如 Jian's Fairness Index。性能和公平在调度系统中往往是矛盾的。例如,调度程序可以优化性能,但代价是以阻止一些任务运行,这就降低了公平。
3、先进先出(FIFO)
可以实现的最基本的算法,被称为先进先出(First In First Out 或 FIFO)调度,有时候也称为先到先服务(First Come First Served 或 FCFS)。
FIFO有一些积极的特性:它很简单,易于实现。而且,对于上述的假设,它的效果很好。
举个例子。想象一下,3 个工作 A、B 和 C 在大致相同的时间(到达时间 = 0)到达系统。因为 FIFO必须将某个工作放在前面,所以我们假设当它们都同时到达时,A 比 B 早一点点,然后 B 比 C 早到达一点点。假设每个工作运行 10s。这些工作的平均周转时间是多少?
如下图所示,A 在 10s 时完成,B 在 20s 时完成,C 在 30s 时完成。因此,这 3 个任务的平均周转时间就是(10 + 20 + 30)/ 3 = 20。

现在开始放宽假设。具体来说,放宽假设1,不再认为每个任务的运行时间相同。此时 FIFO 表现如何?
举个例子来说明不同长度的任务如何导致 FIFO 调度的问题。具体来说,再次假设3个任务(A、B 和 C),但这次 A 运行 100s,而 B 和 C 运行 10s。
如图所示,A 先运行 100s,B 或 C 才有机会运行。因此,系统的平均周转时间是比较高的:110s((100 + 110 + 120)/ 3 = 110)。
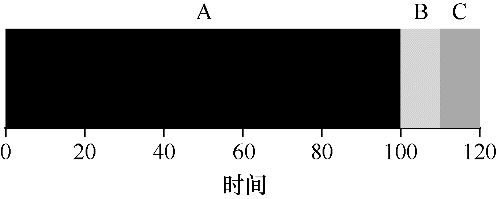
这个问题通常被称为护航效应(convoy effect),一些耗时较少的潜在资源消费者被排在重量级的资源消费者之后。这个调度方案可能让你想起在杂货店只有一个排队队伍的时候,如果看到前面的人装满 3 辆购物车食品并且掏出了支票本,这会等很长时间。
如何开发一种更好的算法来处理任务实际运行时间不一样的场景?
4、最短任务优先(SJF)
事实证明,一个非常简单的方法解决了这个问题。这个新的调度准则被称为最短任务优先(Shortest Job First,SJF):先运行最短的任务,然后是次短的任务,如此下去。
还是上面的例子,但是用 SJF 作为调度策略。下图展示的是运行 A、B 和 C 的结果。它清楚地说明了为什么在考虑平均周转时间的情况下,SJF 调度策略更好。仅通过在 A 之前运行 B 和 C,SJF 将平均周转时间从 110s 降低到 50s((10 + 20 + 120)/3 = 50)。

事实上,考虑到所有工作同时到达的假设,可以证明 SJF 确实是一个最优调度算法。
因此,我们找到了一个用 SJF 进行调度的好方法,但是我们的假设仍然是不切实际的。让我们放宽另一个假设。具体来说,我们可以针对假设 2,现在假设工作可以随时到达,而不是同时到达。这导致了什么问题?
在这里可以再次用一个例子来说明问题。现在,假设 A 在 t = 0 时到达,且需要运行 100s。而 B 和 C 在 t = 10 到达,且各需要运行 10s。用纯 SJF,我们可以得到如下图所示的调度。

从图中可以看出,即使 B 和 C 在 A 之后不久到达,它们仍然被迫等到 A 完成,从而遭遇同样的护航问题。这 3 项工作的平均周转时间为 103.33s,即(100+(110−10)+(120−10))/ 3。
补充:抢占式调度程序
在过去的批处理计算中,开发了一些非抢占式调度程序。这样的系统会将每项工作做完,再考虑是否运行新工作。几乎所有现代化的调度程序都是抢占式的,非常愿意停止一个进程以运行另一个进程。这意味着调度程序采用了前面学习的机制。特别是调度程序可以进行上下文切换,临时停止一个运行进程,并恢复(或启动)另一个进程。
5、最短完成时间优先(STCF)
为了解决这个问题,需要放宽假设 3(工作必须保持运行直到完成)。还需要调度程序本身的一些机制。当 B 和 C 到达时,调度程序可以抢占工作 A,并决定运行另一个工作,或许稍后继续工作 A。根据我们的定义,SJF 是一种非抢占式调度程序,因此存在上述问题。
幸运的是,有一个调度程序完全就是这样做的:向 SJF 添加抢占,称为最短完成时间优先(Shortest Time-to-Completion First,STCF)或抢占式最短作业优先(Preemptive Shortest Job First ,PSJF)调度程序。每当新工作进入系统时,它就会确定剩余工作和新工作中,谁的剩余时间最少,然后调度该工作。因此,在上述例子中,STCF 将抢占 A 并运行 B 和 C。只有在它们完成后,才会继续调度 A 。如下图所示。
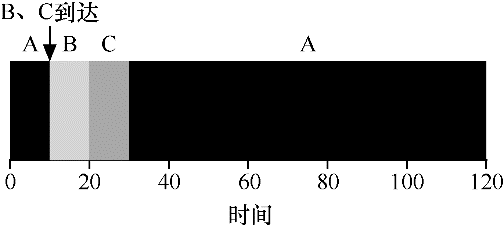
结果是平均周转时间大大提高:50s((120+(20−10)+(30−10))/ 3)。
6、新度量指标:响应时间
因此,如果知道任务长度(假设 5),而且任务只使用 CPU(假设 4),而我们唯一的衡量是周转时间,STCF 将是一个很好的策略。事实上,对于许多早期批处理系统,这些类型的调度算法有一定的意义。
然而,引入分时系统改变了这一切。现在,用户将会坐在终端前面,同时也要求系统的交互性好。因此,一个新的度量标准诞生了:响应时间(response time)。响应时间定义为从任务到达系统到首次运行的时间。更正式的定义是:
T_{响应时间} = T_{首次运行} - T_{到达时间}
例如,如果采取上面的调度(A 在时间 0 到达,B 和 C 在时间 10 达到),那么每个作业的响应时间如下:作业 A 为 0,B 为 0,C 为 10(平均:3.33)。
你可能会想,STCF 以及相关方法在响应时间上并不是很好。例如,如果 3 个工作同时到达,第三个工作必须等待前两个工作全部运行后才能运行。这种方法虽然有很好的周转时间,但对于响应时间和交互性是相当糟糕的。假设你在终端前输入,不得不等待 10s 才能看到系统的回应,只是因为其他一些工作已经在你之前被调度:你肯定不太开心。
因此,还有另一个问题:如何构建对响应时间敏感的调度程序?
7、轮转
为了解决这个问题,将介绍一种新的调度算法,通常被称为轮转(Round-Robin,RR)调度。基本思想很简单:RR 在一个时间片内运行一个工作,然后切换到运行队列中的下一个任务,而不是运行一个任务直到结束。它反复执行,直到所有任务完成。因此,RR有时被称为时间切片。请注意,时间片长度必须是时钟中断周期的倍数。因此,如果时钟中断是每10ms中断一次,则时间片可以是 10ms、20ms 或 10ms 的任何其他倍数。
为了更清晰地理解 RR,举个例子。假设 3 个任务 A、B 和 C 在系统中同时到达,并且它们都希望运行 5s。SJF 调度程序必须运行完当前任务才可运行下一个任务。

相比之下,1s 时间片的 RR 可以快速地循环工作。
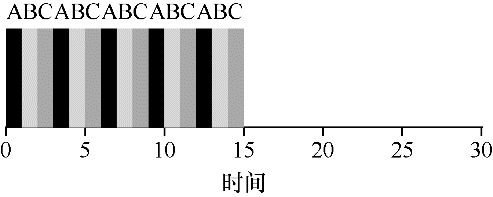
RR 的平均响应时间是:(0 + 1 + 2)/3 = 1; SJF 算法平均响应时间是:(0 + 5 + 10)/ 3 = 5。
时间片长度对于 RR 是至关重要的。越短,RR 在响应时间上表现越好。然而,时间片太短是有问题的:突然上下文切换的成本将影响整体性能。因此,系统设计者需要权衡时间片的长度,使其足够长,以便摊销上下文切换成本,而又不会使系统不及时响应。
当系统某些操作有固定成本时,通常会使用摊销技术。通过减少成本的频度(即执行较少次的操作),系统的总成本就会降低。例如,如果时间片设置为 10ms,并且上下文切换时间为 1ms,那么浪费大约 10% 的时间用于上下文切换。如果要摊销这个成本,可以把时间片增加到 100ms。在这种情况下,不到 1% 的时间用于上下文切换,因此时间片带来的成本就被摊销了。
请注意,上下文切换的成本不仅仅来自保存和恢复少量寄存器的操作系统操作。程序运行时,它们在CPU高速缓存、TLB、分支预测器和其他片上硬件中建立了大量的状态。切换到另一个工作会导致此状态被刷新,且与当前运行的作业相关的新状态被引入,这可能导致显著的性能成本。
如果响应时间是唯一指标,那么带有合理时间片的 RR,就会是非常好的调度程序。但是周转时间呢?再来看看例子。A、B 和 C,每个运行时间为 5s,同时到达,RR是具有 1s 时间片的调度程序。从上图可以看出,A 在 13 完成,B 在 14,C 在 15,平均 14。相当可怕!
这并不奇怪,兑于周转时间来说,RR 确实是最糟糕的策略之一。直观地说,这应该是有意义的:RR所做的正是延伸每个工作,只运行每个工作一小段时间,就转向下一个工作。因为周转时间只关心作业何时完成,RR 几乎是最差的,在很多情况下甚至比简单的 FIFO 更差。
更一般地说,任何公平的政策(如 RR),即在小规模的时间内将 CPU 均匀分配到活动进程之间,在周转时间这类指标上表现不佳。事实上,这是固有的权衡:如果愿意不公平,可以运行较短的工作直到完成,但是要以响应时间为代价。如果重视公平性,则响应时间会较短,但会以周转时间为代价。这种权衡在系统中很常见。
提示:重叠可以提高利用率
如有可能,重叠操作可以最大限度地提高系统的利用率。重叠在许多不同的领域很有用,包括执行磁盘 I/O 或将消息发送到远程机器时。在任何一种情况下,开始操作然后切换到其他工作都是一个好主意,这也提高了系统的整体利用率和效率。
8、结合 IO
首先,放宽假设 4:所有程序都执行 I/O。想象一下没有任何输入的程序:每次都会产生相同的输出。设想一个没有输出的程序:它就像谚语所说的森林里倒下的树,没有人看到它。它的运行并不重要。
调度程序显然要在工作发起 I/O 请求时做出决定,因为当前正在运行的作业在 I/O 期间不会使用 CPU,它被阻塞等待 I/O 完成。如果将 I/O 发送到硬盘驱动器,则进程可能会被阻塞几毫秒或更长时间,具体取决于驱动器当前的 I/O 负载。因此,这时调度程序应该在 CPU 上安排另一项工作。
调度程序还必须在 I/O 完成时做出决定。发生这种情况时,会产生中断,操作系统运行并将发出 I/O 的进程从阻塞状态移回就绪状态。当然,它甚至可以决定在那个时候运行该项工作。操作系统应该如何处理每项工作?
为了更好地理解这个问题,假设有两项工作 A 和 B,每项工作需要 50ms 的 CPU 时间。但是,有一个明显的区别:A 运行 10ms,然后发出 I/O 请求(假设每个 I/O 请求都需要10ms),而 B 只是使用CPU 50ms,不执行 I/O。调度程序先运行 A,然后运行 B。
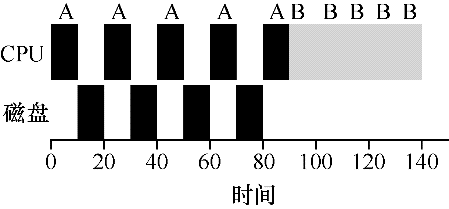
假设正在尝试构建 STCF 调度程序。这样的调度程序应该如何考虑到这样的事实,即 A 分解成 5 个 10ms 子工作,而 B 仅仅是单个 50ms CPU 需求?显然,仅仅运行一个工作,然后运行另一个工作,而不考虑 I/O 是没有意义的。
一种常见的方法是将 A 的每个 10ms 的子工作视为一项独立的工作。因此,当系统启动时,它的选择是调度 10ms 的 A,还是 50ms 的 B。对于 STCF,选择是明确的:选择较短的一个,在这种情况下是 A。然后,A 的工作已完成,只剩下 B,并开始运行。然后提交 A 的一个新子工作,它抢占 B 并运行 10ms。这样做可以实现重叠,一个进程在等待另一个进程的I/O完成时使用CPU,系统因此得到更好的利用。
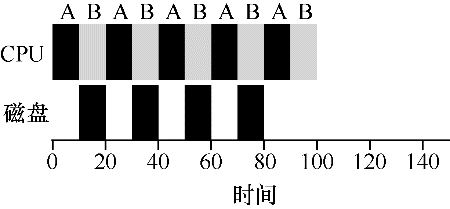
这样就看到了调度程序可能如何结合 I/O。通过将每个 CPU 突发事件作为一项工作,调度程序确保“交互”的进程频繁运行。当这些交互式作业正在执行 I/O 时,其他 CPU 密集型作业将运行,从而更好地利用处理器。
9、无法预知
有了应对 I/O 的基本方法,我们来到最后的假设 5:调度程序知道每个工作的长度。如前所述,这可能是可以做出的最糟糕的假设。事实上,在一个通用的操作系统中,操作系统通常对每个作业的长度知之甚少。因此,如何建立一个没有这种先验知识的 SJF/STCF?更进一步,如何能够将已经看到的一些想法与 RR 调度程序结合起来,以便响应时间也变得相当不错?
10、小结
本章介绍了调度的基本思想,并描述了两类方法。第一类是运行最短的工作,从而优化周转时间。第二类是交替运行所有工作,从而优化响应时间。但很难做到“鱼与熊掌兼得”,这是系统中常见的、固有的折中。我们也看到了如何将 I/O 结合到场景中,但仍未解决操作系统根本无法看到未来的问题。后面的主题将介绍如何通过构建一个调度程序,利用最近的历史预测未来,从而解决这个问题。这个调度程序称为多级反馈队列。


