阅读笔记主要来自原书第 10 章。该章对多处理器下进程的调度策略进行了系统性的介绍,可以帮助读者更好地了解多处理器下进程调度存在的问题及常用的处理策略。
0、前言
本章将介绍多处理器调度的基础知识。
过去很多年,多处理器系统只存在于高端服务器中。现在,它们越来越多地出现在个人 PC、笔记本电脑和移动设备上。多核处理器将多个 CPU 核组装在一块芯片上,是这种扩散的根源。由于计算机的架构师们当时难以让单核 CPU 在更快的同时又不增加太多功耗,所以这种多核 CPU 很快就变得流行。
但多核 CPU 带来了许多困难。主要困难是典型的应用程序都只使用一个 CPU,增加了更多的 CPU 并没有让这类程序运行得更快。为了解决这个问题,不得不重写这些应用程序,使之能并行执行,可能使用多线程。多线程应用可以将工作分散到多个 CPU 上,因此 CPU 资源越多就运行越快。
除了应用程序,操作系统遇到的一个新的问题是多处理器调度。到目前为止,我们讨论了许多单处理器调度的原则,那么如何将这些想法扩展到多处理器上呢?还有什么新的问题需要解决?因此,我们的问题如下。
操作系统应该如何在多CPU上调度工作?会遇到什么新问题?已有的技术依旧适用吗?是否需要新的思路?
1、背景:多处理器架构
为了理解多处理器调度带来的新问题,必须先知道它与单 CPU 之间的基本区别。区别的核心在于对硬件缓存(cache)的使用(如下图所示),以及多处理器之间共享数据的方式。

在单 CPU 系统中,存在多级的硬件缓存,一般来说会让处理器更快地执行程序。缓存是很小但很快的存储设备,通常拥有内存中最热的数据的备份。相比之下,内存很大且拥有所有的数据,但访问速度较慢。通过将频繁访问的数据放在缓存中,系统似乎拥有又大又快的内存。
举个例子,假设一个程序需要从内存中加载指令并读取一个值,系统只有一个 CPU,拥有较小的缓存(如 64
程序第一次读取数据时,数据在内存中,因此需要花费较长的时间(可能数十或数百纳秒)。处理器判断该数据很可能会被再次使用,因此将其放入 CPU 缓存中。如果之后程序再次需要使用同样的数据,CPU 会先查找缓存。因为在缓存中找到了数据,所以取数据快得多(比如几纳秒),程序也就运行更快。
缓存是基于局部性的概念,局部性有两种,即时间局部性和空间局部性。时间局部性是指当一个数据被访问后,它很有可能会在不久的将来被再次访问,比如循环代码中的数据或指令本身。而空间局部性指的是,当程序访问地址为 x 的数据时,很有可能会紧接着访问x周围的数据,比如遍历数组或指令的顺序执行。由于这两种局部性存在于大多数的程序中,硬件系统可以很好地预测哪些数据可以放入缓存,从而运行得很好。
有趣的部分来了:如果系统有多个处理器,并共享同一个内存,如下图所示,会怎样呢?

事实证明,多 CPU 的情况下缓存要复杂得多。例如,假设一个运行在 CPU 1 上的程序从内存地址 A 读取数据。由于不在 CPU 1 的缓存中,所以系统直接访问内存,得到值 D。程序然后修改了地址 A 处的值,只是将它的缓存更新为新值 D’。将数据写回内存比较慢,因此系统通常会稍后再做。假设这时操作系统中断了该程序的运行,并将其交给 CPU 2,重新读取地址 A 的数据,由于 CPU 2 的缓存中并没有该数据,所以会直接从内存中读取,得到了旧值 D,而不是正确的值 D’。
这一普遍的问题称为缓存一致性问题。硬件提供了这个问题的基本解决方案:通过监控内存访问,硬件可以保证获得正确的数据,并保证共享内存的唯一性。在基于总线的系统中,一种方式是使用总线窥探。每个缓存都通过监听链接所有缓存和内存的总线,来发现内存访问。如果 CPU 发现对它放在缓存中的数据的更新,会作废本地副本(从缓存中移除),或更新它(修改为新值)。
bus snooping 方法简单,但要需要每时每刻监听总线上的一切活动。我们需要明白的一个问题是不管别的 CPU 私有 Cache 是否缓存相同的数据,都需要发出一次广播事件。这在一定程度上加重了总线负载,也增加了读写延迟。针对该问题,提出了一种状态机机制降低带宽压力。这就是 MESI。详情可参考多核 Cache 一致性。
2、别忘了同步
既然缓存已经做了这么多工作来提供一致性,应用程序(或操作系统)还需要关心共享数据的访问吗?依然需要!
跨CPU访问(尤其是写入)共享数据或数据结构时,需要使用互斥原语(比如锁),才能保证正确性(其他方法,如使用无锁(lock-
为了更具体,我们设想这样的代码序列,用于删除共享链表的一个元素,如下所示。假设两个 CPU 上的不同线程同时进入这个函数。如果线程 1 执行第一行,会将 head 的当前值存入它的 tmp 变量。如果线程 2 接着也执行第一行,它也会将同样的 head 值存入它自己的私有 tmp 变量(tmp 在栈上分配,因此每个线程都有自己的私有存储)。因此,两个线程会尝试删除同一个链表头,而不是每个线程移除一个元素,这导致了各种问题(比如在第 4 行重复释放头元素,以及可能两次返回同一个数据)。
typedef struct __Node_t {
int value;
struct __Node_t *next;
} Node_t;
int List_Pop() {
Node_t *tmp = head; // remember old head ...
int value = head->value; // ... and its value
head = head->next; // advance head to next pointer
free(tmp); // free old head
return value; // return value at head
}
当然,让这类函数正确工作的方法是加锁。这里只需要一个互斥锁(即 pthread_
3、最后一个问题:缓存亲和度
在设计多处理器调度时遇到的最后一个问题,是所谓的缓存亲和度(cache affinity)。这个概念很简单:一个进程在某个CPU上运行时,会在该 CPU 的缓存中维护许多状态。下次该进程在相同 CPU 上运行时,由于缓存中的数据而执行得更快。相反,在不同的 CPU 上执行,会由于需要重新加载数据而很慢(好在硬件保证的缓存一致性可以保证正确执行)。因此多处理器调度应该考虑到这种缓存亲和性,并尽可能将进程保持在同一个 CPU 上。
4、单队列调度
上面介绍了一些背景,现在来讨论如何设计一个多处理器系统的调度程序。最基本的方式是简单地复用单处理器调度的基本架构,将所有需要调度的工作放入一个单独的队列中,我们称之为单队列多处理器调度(Single Queue Multiprocessor Scheduling,SQMS)。这个方法最大的优点是简单。它不需要太多修改,就可以将原有的策略用于多个 CPU,选择最适合的工作来运行(例如,如果有两个CPU,它可能选择两个最合适的工作)。
然而,SQMS 有几个明显的短板。第一个是缺乏可扩展性。为了保证在多 CPU 上正常运行,调度程序的开发者需要在代码中通过加锁来保证原子性,如上所述。在 SQMS 访问单个队列时(如寻找下一个运行的工作),锁确保得到正确的结果。
然而,锁可能带来巨大的性能损失,尤其是随着系统中的 CPU 数增加时。随着这种单个锁的争用增加,系统花费了越来越多的时间在锁的开销上,较少的时间用于系统应该完成的工作。
SQMS 的第二个主要问题是缓存亲和性。比如,假设我们有 5 个工作(A、B、C、D、E)和 4 个处理器。调度队列如下:

一段时间后,假设每个工作依次执行一个时间片,然后选择另一个工作,下面是每个 CPU 可能的调度序列:

由于每个 CPU 都简单地从全局共享的队列中选取下一个工作执行,因此每个工作都不断在不同 CPU之间转移,这与缓存亲和的目标背道而驰。
为了解决这个问题,大多数 SQMS 调度程序都引入了一些亲和度机制,尽可能让进程在同一个 CPU 上运行。保持一些工作的亲和度的同时,可能需要牺牲其他工作的亲和度来实现负载均衡。例如,针对同样的 5 个工作的调度如下:

这种调度中,A、B、C、D 这 4 个工作都保持在同一个 CPU 上,只有工作 E 不断地来回迁移,从而尽可能多地获得缓存亲和度。为了公平起见,之后我们可以选择不同的工作来迁移。但实现这种策略可能很复杂。
可以看到,SQMS 调度方式有优势也有不足。优势是能够从单 CPU 调度程序很简单地发展而来,根据定义,它只有一个队列。然而,它的扩展性不好(由于同步开销有限),并且不能很好地保证缓存亲和度。
5、多队列调度
正是由于单队列调度程序的这些问题,有些系统使用了多队列的方案,比如每个 CPU 一个队列。称之为多队列多处理器调度(Multi-
在 MQMS 中,基本调度框架包含多个调度队列,每个队列可以使用不同的调度规则,比如轮转或其他任何可能的算法。当一个工作进入系统后,系统会依照一些启发性规则(如随机或选择较空的队列)将其放入某个调度队列。这样一来,每个CPU调度之间相互独立,就避免了单队列的方式中由于数据共享及同步带来的问题。
例如,假设系统中有两个 CPU(CPU 0 和 CPU 1)。这时一些工作进入系统:A、B、C 和 D。由于每个 CPU 都有自己的调度队列,操作系统需要决定每个工作放入哪个队列。可能像下面这样做:

根据不同队列的调度策略,每个 CPU 从两个工作中选择,决定谁将运行。例如,利用轮转,调度结果可能如下所示:

MQMS 比 SQMS 有明显的优势,它天生更具有可扩展性。队列的数量会随着 CPU 的增加而增加,因此锁和缓存争用的开销不是大问题。此外,MQMS 天生具有良好的缓存亲和度。所有工作都保持在固定的 CPU 上,因而可以很好地利用缓存数据。
但是,如果稍加注意,可能会发现有一个新问题,即负载不均。假定和上面设定一样(4 个工作,2 个 CPU),但假设一个工作(如 C)这时执行完毕。现在调度队列如下:

如果对系统中每个队列都执行轮转调度策略,会获得如下调度结果:

从图中可以看出,A 获得了 B 和 D 两倍的 CPU 时间,这不是期望的结果。更糟的是,假设 A 和 C 都执行完毕,系统中只有 B 和 D。调度队列看起来如下:
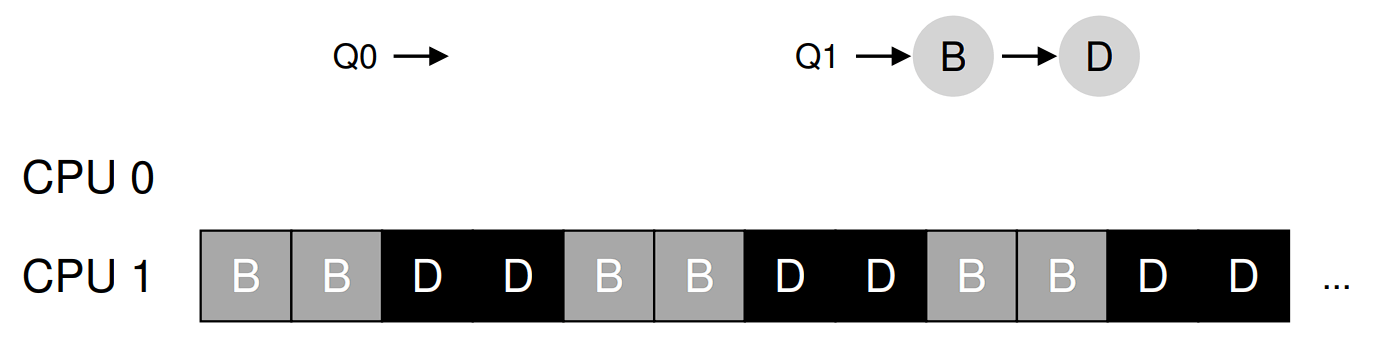
因此 CPU 使用时间线看起来令人难过。
所以多队列多处理器调度程序应该如何处理负载不均问题,从而更好地实现预期的调度目标?
最明显的答案是让工作移动,这种技术我们称为迁移。通过工作的跨 CPU 迁移,可以真正实现负载均衡。
来看两个例子就更清楚了。同样,有一个 CPU 空闲,另一个 CPU 有一些工作。

在这种情况下,期望的迁移很容易理解:操作系统应该将 B 或 D 迁移到 CPU0。这次工作迁移导致负载均衡,皆大欢喜。
更棘手的情况是较早一些的例子,A 独自留在 CPU 0 上,B 和 D 在 CPU 1 上交替运行。
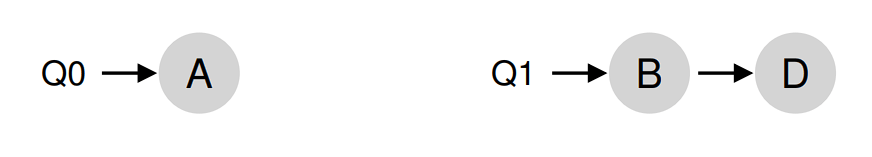
在这种情况下,单次迁移并不能解决问题。应该怎么做呢?答案是不断地迁移一个或多个工作。一种可能的解决方案是不断切换工作,如下面的时间线所示。可以看到,开始的时候 A 独享 CPU 0,B 和 D 在 CPU 1。一些时间片后,B 迁移到 CPU 0 与 A 竞争,D 则独享 CPU 1 一段时间。这样就实现了负载均衡。

当然,这种方法也有让人抓狂的地方——如果太频繁地检查其他队列,就会带来较高的开销,可扩展性不好,而这是多队列调度最初的全部目标!相反,如果检查间隔太长,又可能会带来严重的负载不均。找到合适的阈值仍然是黑魔法:),这在系统策略设计中很常见。
6、Linux 多处理器调度
有趣的是,在构建多处理器调度程序方面,Linux 社区一直没有达成共识。一直以来,存在 3 种不同的调度程序:O(
O(
7、小结
本章介绍了多处理器调度的不同方法。其中单队列的方式(SQMS)比较容易构建,负载均衡较好,但在扩展性和缓存亲和度方面有着固有的缺陷。多队列的方式(MQMS)有很好的扩展性和缓存亲和度,但实现负载均衡却很困难,也更复杂。无论采用哪种方式,都没有简单的答案:构建一个通用的调度程序仍是一项令人生畏的任务,因为即使很小的代码变动,也有可能导致巨大的行为差异。