本文主要分享我使用大模型(LLM)和 Agent 工具的一些心得体验,可能存在不对之处,欢迎指正。
注:LLM 指大语言模型,比如 Claude Opus 4.8、GPT-
零、前言
最早使用大模型应该是在 2022 年,印象中当时用的应该是Chat
直到今年,Agent 工具大火,我也尝试用 Agent 接入大模型来完成一些任务,到目前用了也有几个月了,最直观的感受就是 Chatbot 形式类似一个会思考的高级搜索引擎,它主要根据你的问题给你回答,你再基于它的回答进行某些操作,并将操作结果反馈给它,从而进行进一步的探索,在这个过程中通过“人+大模型”反馈迭代的形式解决问题或完成任务。而 Agent 形式类似一个不仅会思考还会使用工具的助理,它可以根据问题/任务自行完成分析、操作并根据操作结果进行进一步探索,相当于“Agent+大模型”反馈迭代,这极大减少了人的参与,提升了任务的处理效率。某种程度上相当于从“Human in the loop”进化成“Agent in the loop”。
2026-
07- 18 更新: 目前国产大模型”御三家“的旗舰(Deep
Seek- V4- Pro、GLM- 5.2、Kimi K3)都体验过了,GLM- 5.2 和 Kimi K3 的效果也都不错。 GLM-
5.2 是通过火山引擎的 Coding Plan 和 Agent Plan 体验的,主要用来做现有几个 toy 项目的优化了,使用时感觉良好,特别是在任务评估和规划上做得不错,会主动提供多个选择。有一点不爽的是,它在检验时会主动调用无头浏览器“识图”,但是它只是个文本模型,所以会导致对话异常,需要回滚,这可能是系统提示词没设置好导致的。 Kimi K3 是直接在官网体验的,开通了入门的 Andante 计划,一共让它做了四个深度调研,每个任务都超过 1 小时,直接用掉了 72.81% 的额度:),但是效果还是蛮令人惊艳的,调研报告图文并茂,完成度很高。此外,虽然现在是通过在线界面进行交互,但实际上完成任务的是在沙箱中运行的 agent,各种技能一应俱全,调研报告中的图也是通过编写执行 python 脚本现画的,类似 Open
AI 的 Chat GPT Work。 另外,Open
AI 的 GPT‑ 5.6 Sol 是我目前能稳定使用的综合性能最强的大模型,虽然也有一些小问题,但在 Codex 经常重置额度并赠送重置机会以及暂时不限制 5h 额度的加持下,性价比无敌。 总的来说,目前日常使用的大模型主要还是 GPT‑
5.6 Sol 和 Deep Seek- V4- Pro。Codex( GPT‑ 5.6 Sol) 用于编程,Chat GPT( GPT‑ 5.6 Sol) 用于问答,Deep Seek- V4- Pro 用于 Hermes 和项目中的 AI 点评总结。当然,对于新出的能用上的大模型,我也会尝试体验下。
一、模型 / Agent 产品
考虑到中转站存在注水/数据泄漏等问题,所以目前主要还是使用官方渠道的服务。当前我在用的产品主要有以下三个。
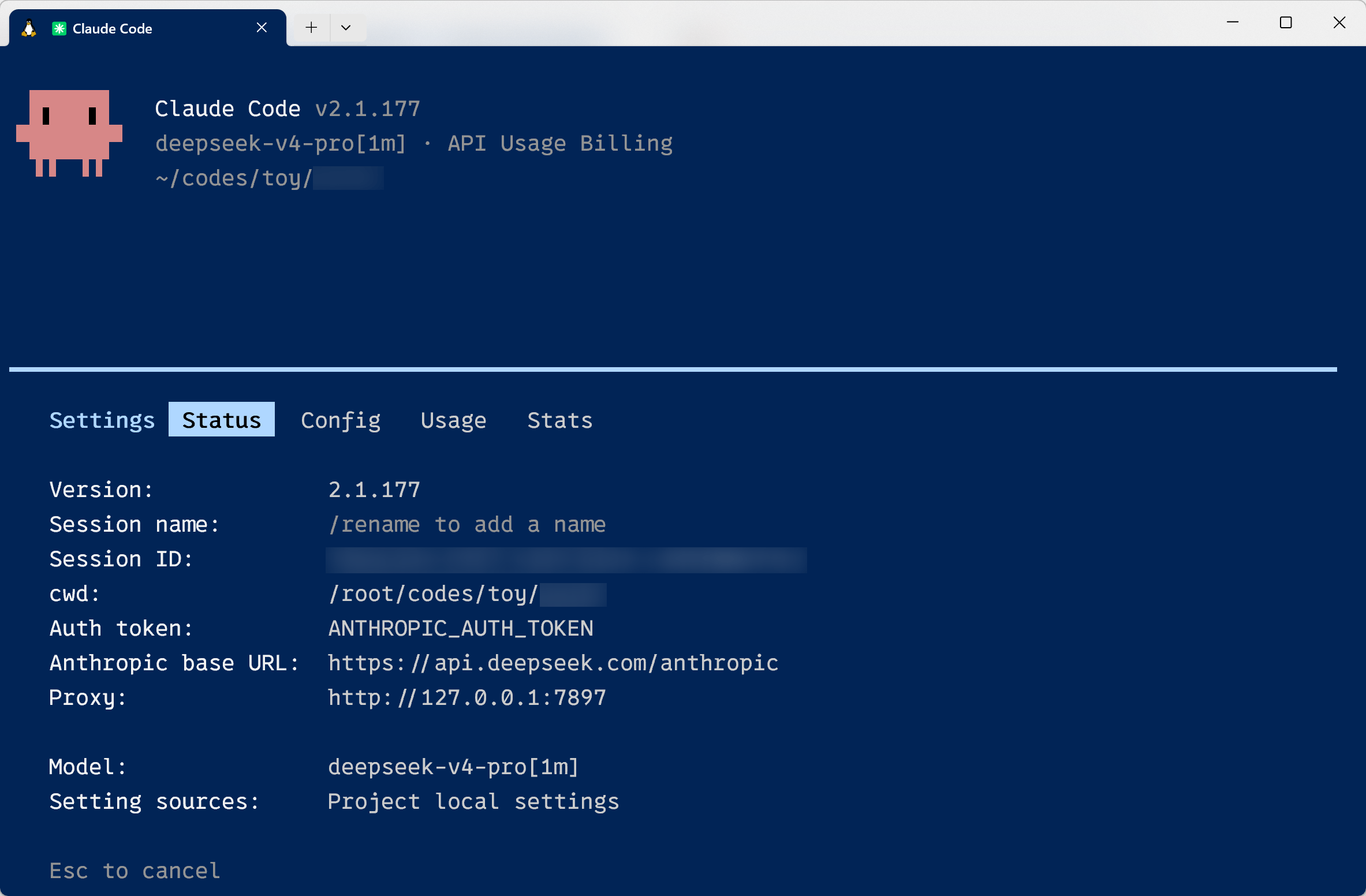
1、Claude Code (CLI) + DeepSeek V4 Pro
由于内外同时存在的限制,且 Anthropic 经常封号,所以难以直接使用它自家的模型,我是配置的 Deep
整体体验还行,能用。基本上开箱即用(国内通过 npm 安装好 Claude Code,然后配置完 API 就可以直接使用了),不用额外折腾,更重要的是,Deep
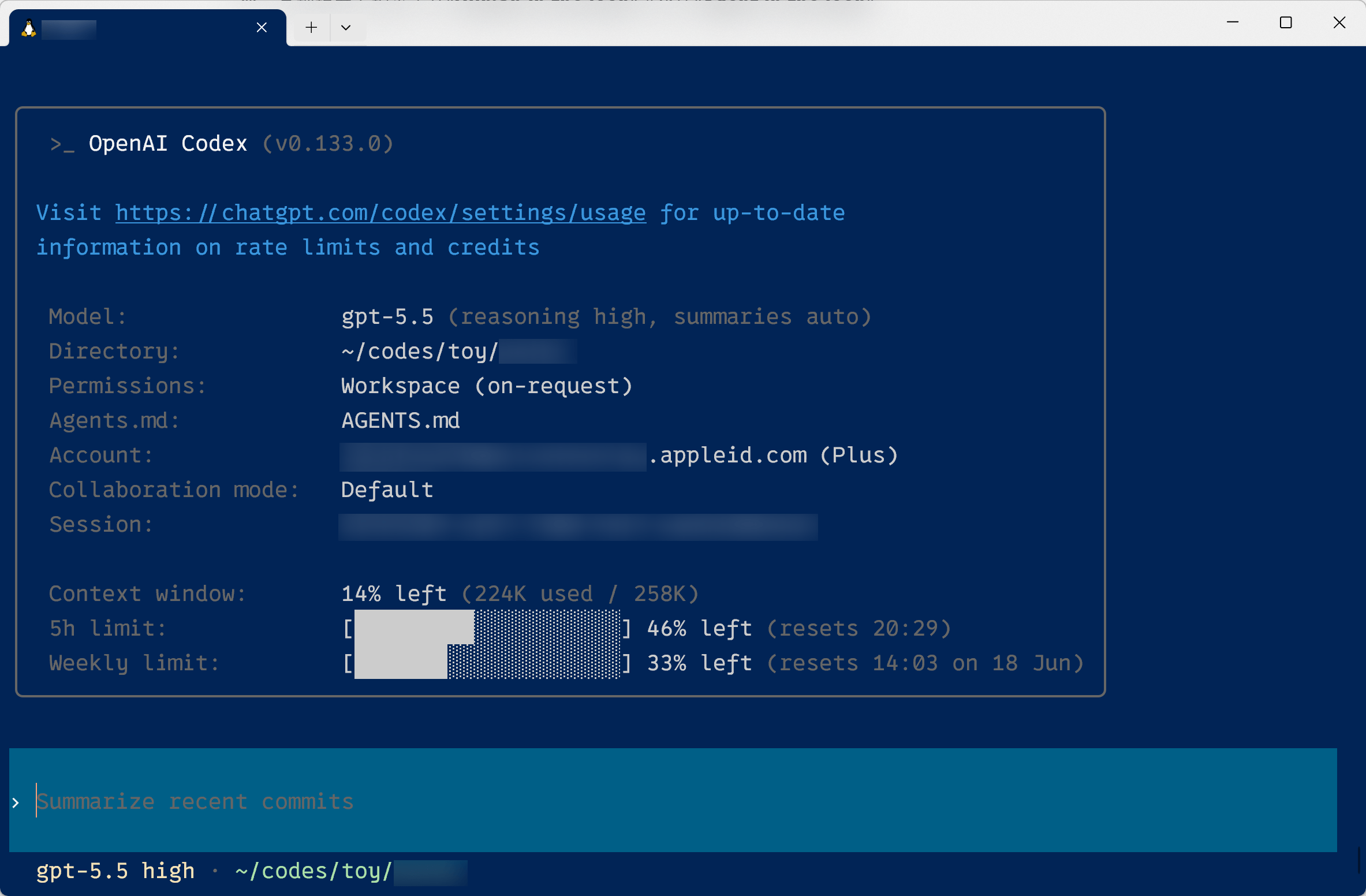
2、Codex (CLI) + GPT-5.5
虽然同样存在内外限制,但是相对来说 Open
整体体验很不错,好用。GPT-
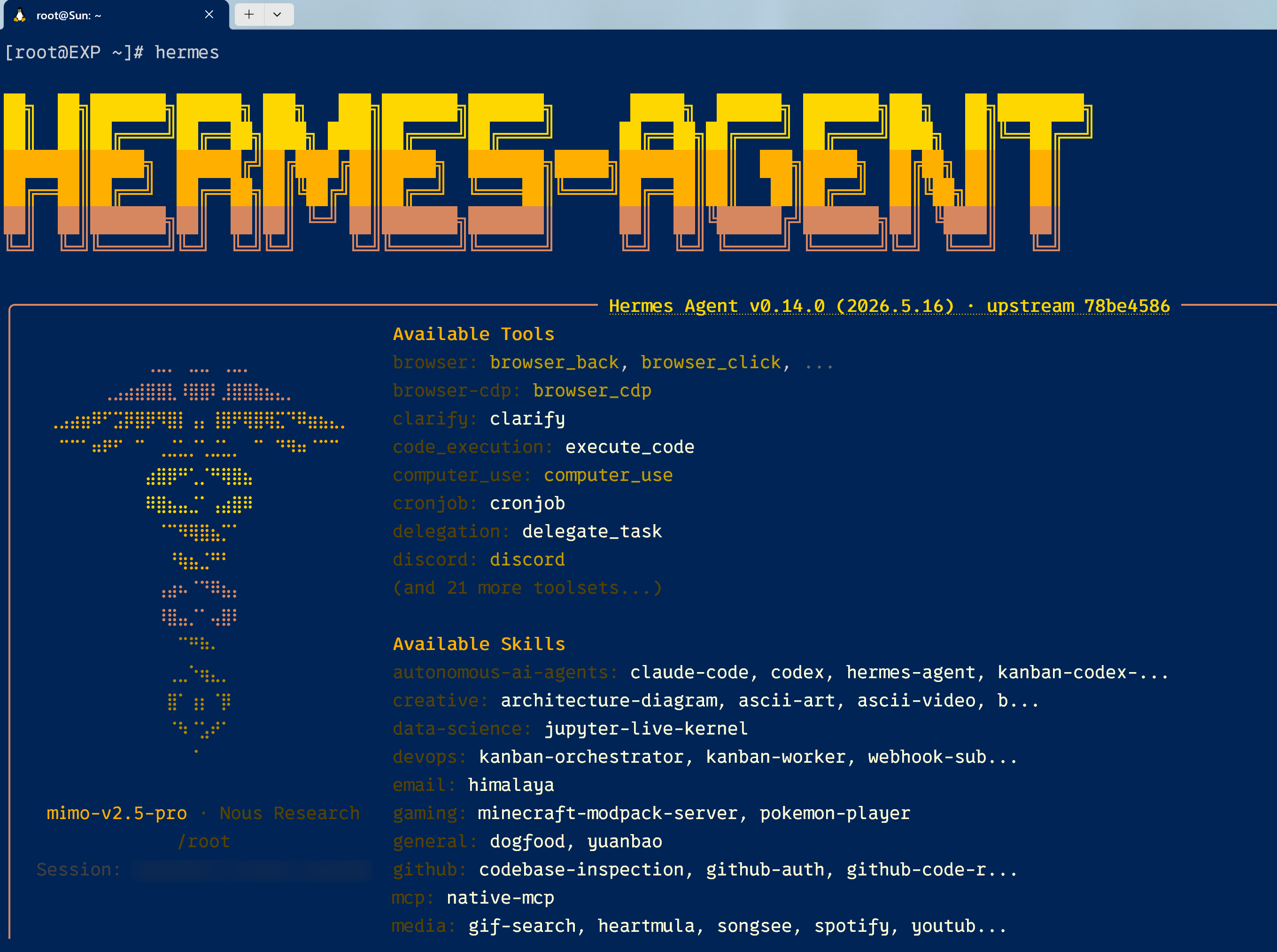
3、Hermes + MiMo-V2.5-Pro
一开始是在服务器上通过 docker 部署的 Open
整体体验一般,主要还是没有什么通用类 Agent 的需求,日常偏轻度使用。
二、项目实践
主要介绍下使用 Claude Code 和 Codex 在业余时间开发的几个小项目,这些项目的每一行代码和文档等都是 AI 写的,包括 git 提交和部署到服务器上也都是 AI 完成的。
这些项目主要偏数据抓取、分析与可视化,后端均使用 Python。整体而言完成度还算可以,目前还在持续迭代中,部分已开源并部署,感兴趣的朋友可以点开看一看。
1、全球资产看板
追踪全球指数、资产、ETF 与 QDII 主动基金,覆盖实时概览、区间收益、回撤风险和基金 T 日估算净值。
- Agent:Codex(
GPT- 5.5) + Claude Code( Deep Seek- V4- Pro) -
技术栈:Type
Script( React) + Python( Flask + SQLite) + Vite
最开始是做的基金估值小助手,当时主要是想试下 Claude Code 配 Deep
用 Claude Code(
在 AI Coding 的过程中,我发现 GPT-

项目效果图如下。
(1)、概览页,展示当天大盘涨跌情况,包括 A 股、美股、亚太市场、黄金等资产及热门 ETF;
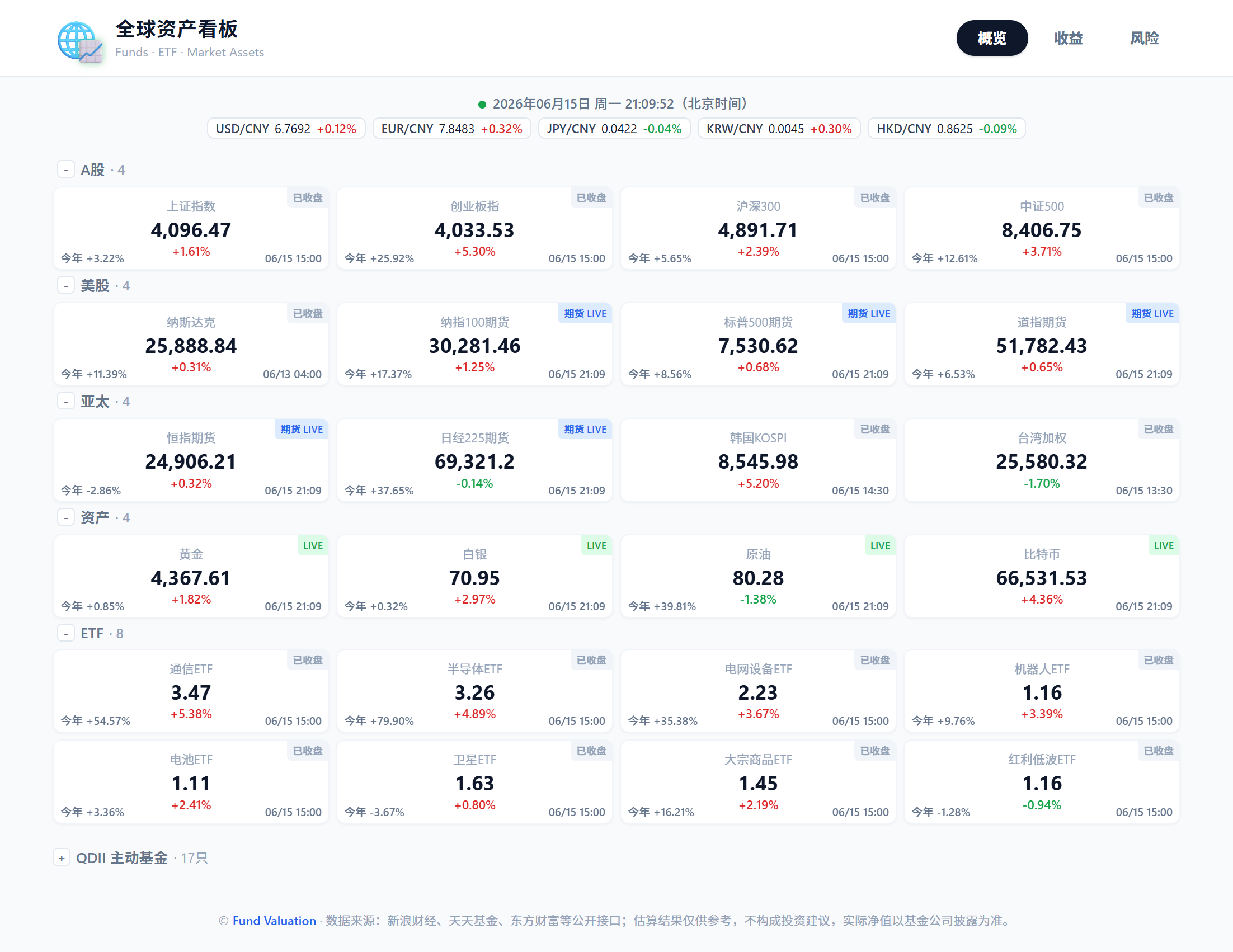
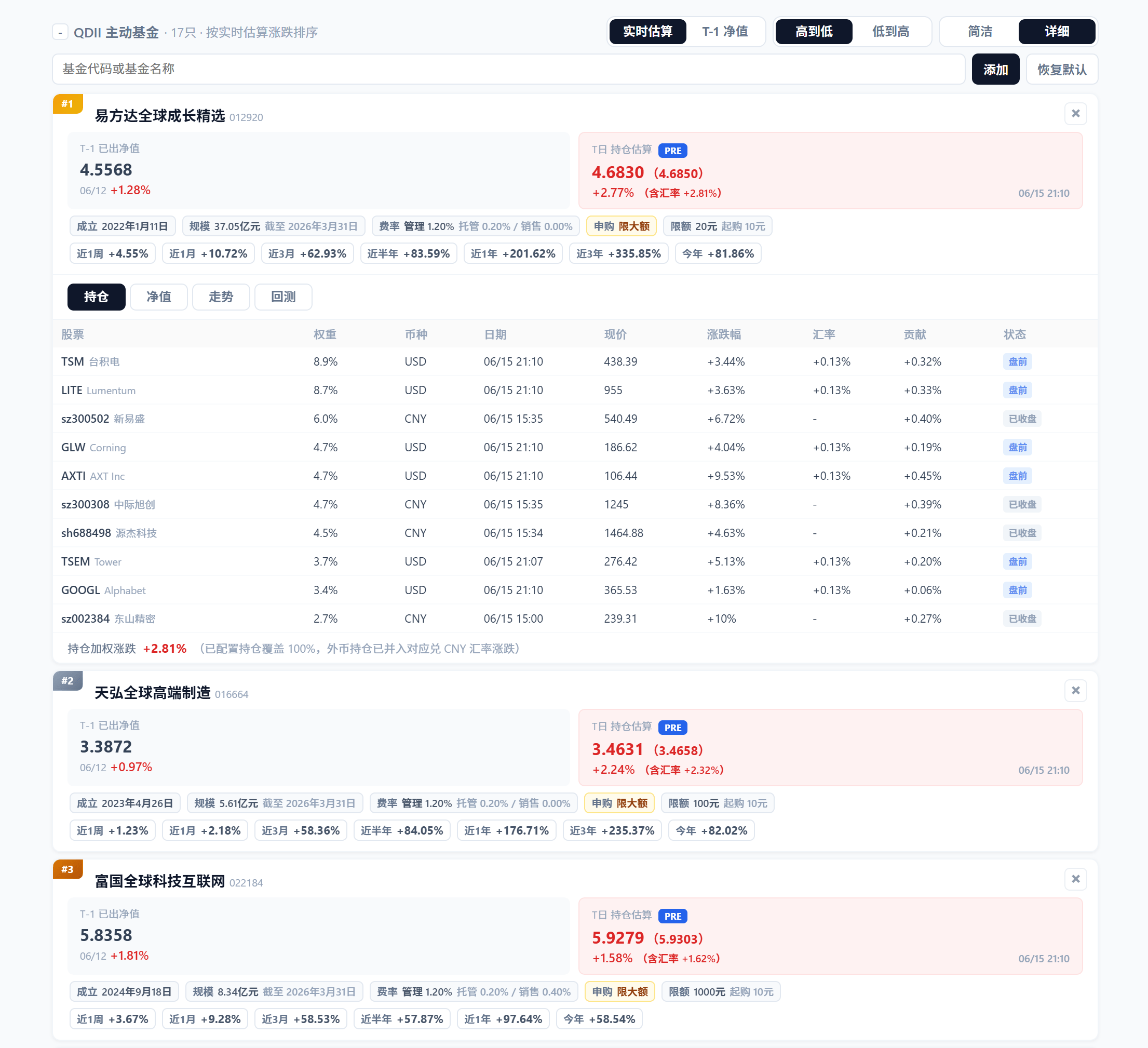
(2)、概览页,展示 QDII 主动基金实时估值和 T-
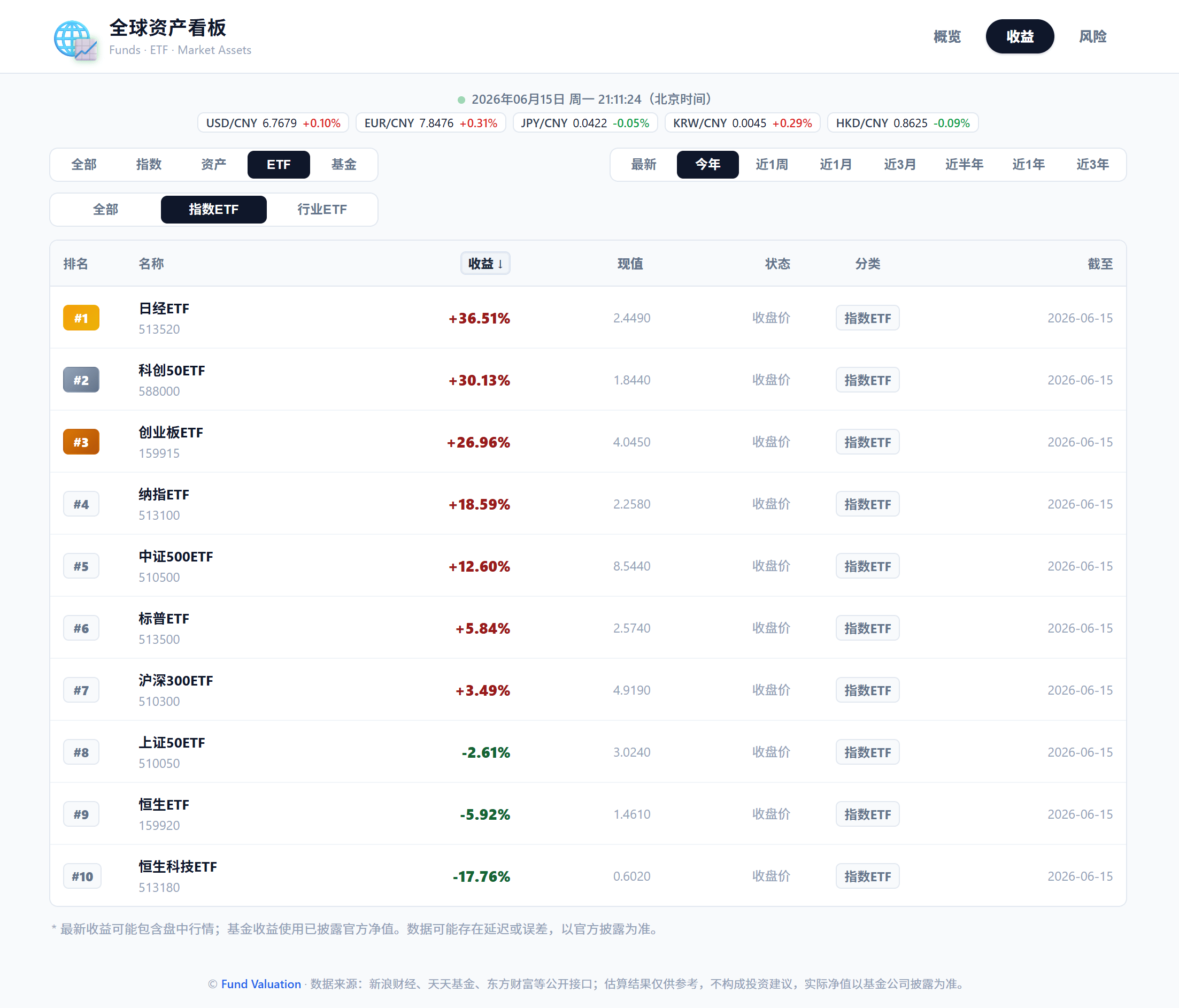
(3)、收益页,按序展示各类资产不同时间段涨跌情况
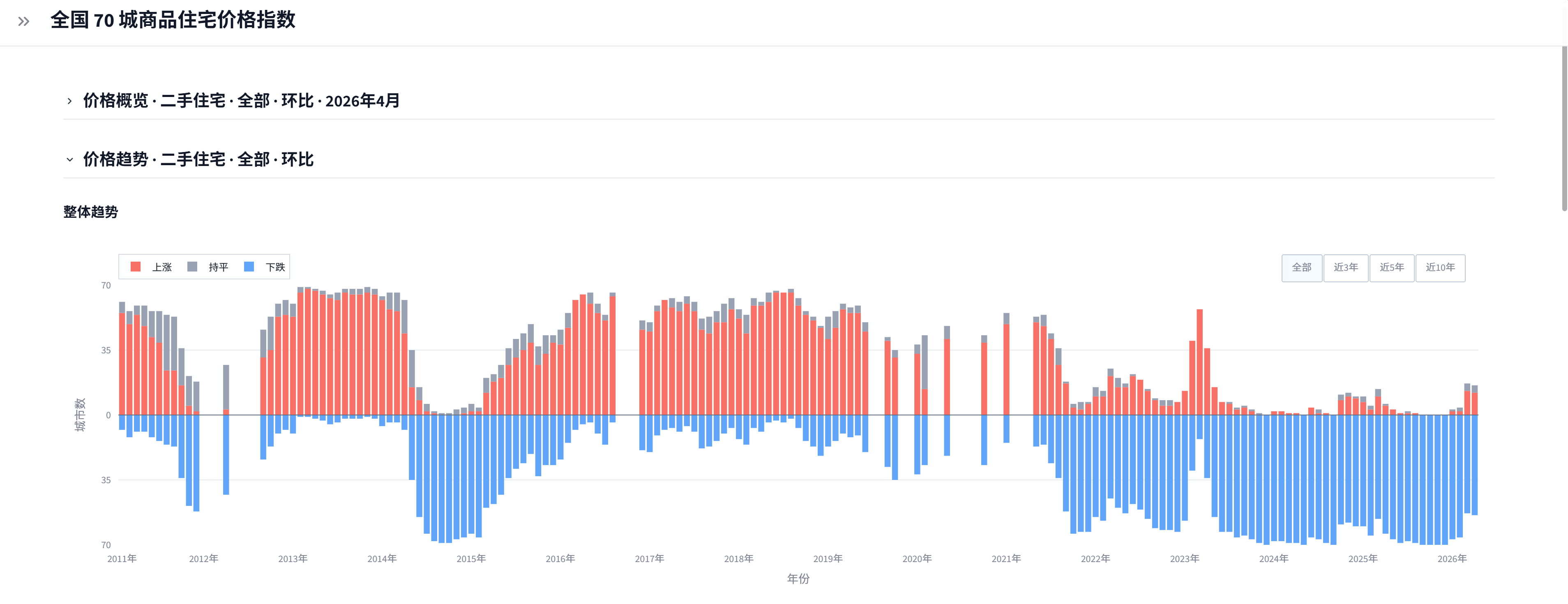
2、全国 70 城商品住宅价格指数
从国家统计局获取“70 个大中城市商品住宅销售价格变动情况”,用 Streamlit 做交互式可视化。
- Agent:Codex(
GPT- 5.5) -
技术栈:Python(
streamlit)
这个项目比较简单,完全使用 Codex(
项目效果图如下。
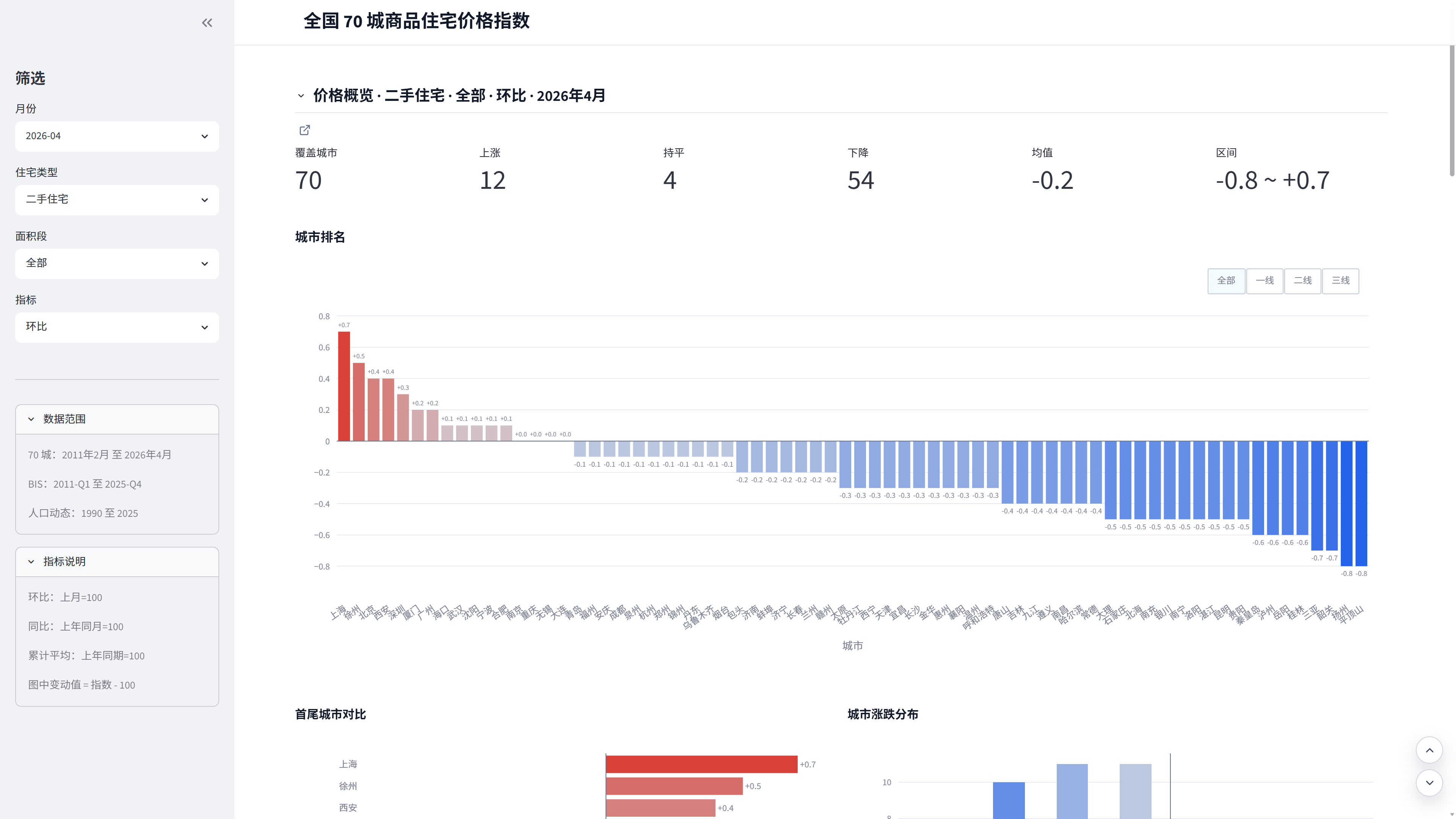
(1)、2026 年 4 月二手住宅全部面积段环比涨跌情况;
(2)、从 2021 年到 2026 年二手住宅全部面积段环比涨跌情况,当前趋势一目了然:)
3、微博群聊分析
本地微博群聊消息看板,用于采集、归档和分析微博群聊消息。通过微博内部 API 直接拉取消息数据,存入数据库,并提供三层看板页面进行数据分析与消息检索。
- Agent:Claude Code(
Deep Seek- V4- Pro) + Codex( GPT- 5.5) -
技术栈:Python(
Flask + SQLite + jieba)
这个项目还是挺有意思的,根据微博群聊消息分析大家讨论的热门话题,并生成成员画像。一开始是用 Codex(
该项目的核心在于分词,分词效果的好坏直接影响数据分析的质量。目前是采用 jieba + 自定义词典 + 停用词表进行分词,手动过滤了不少:),效果还算可以。
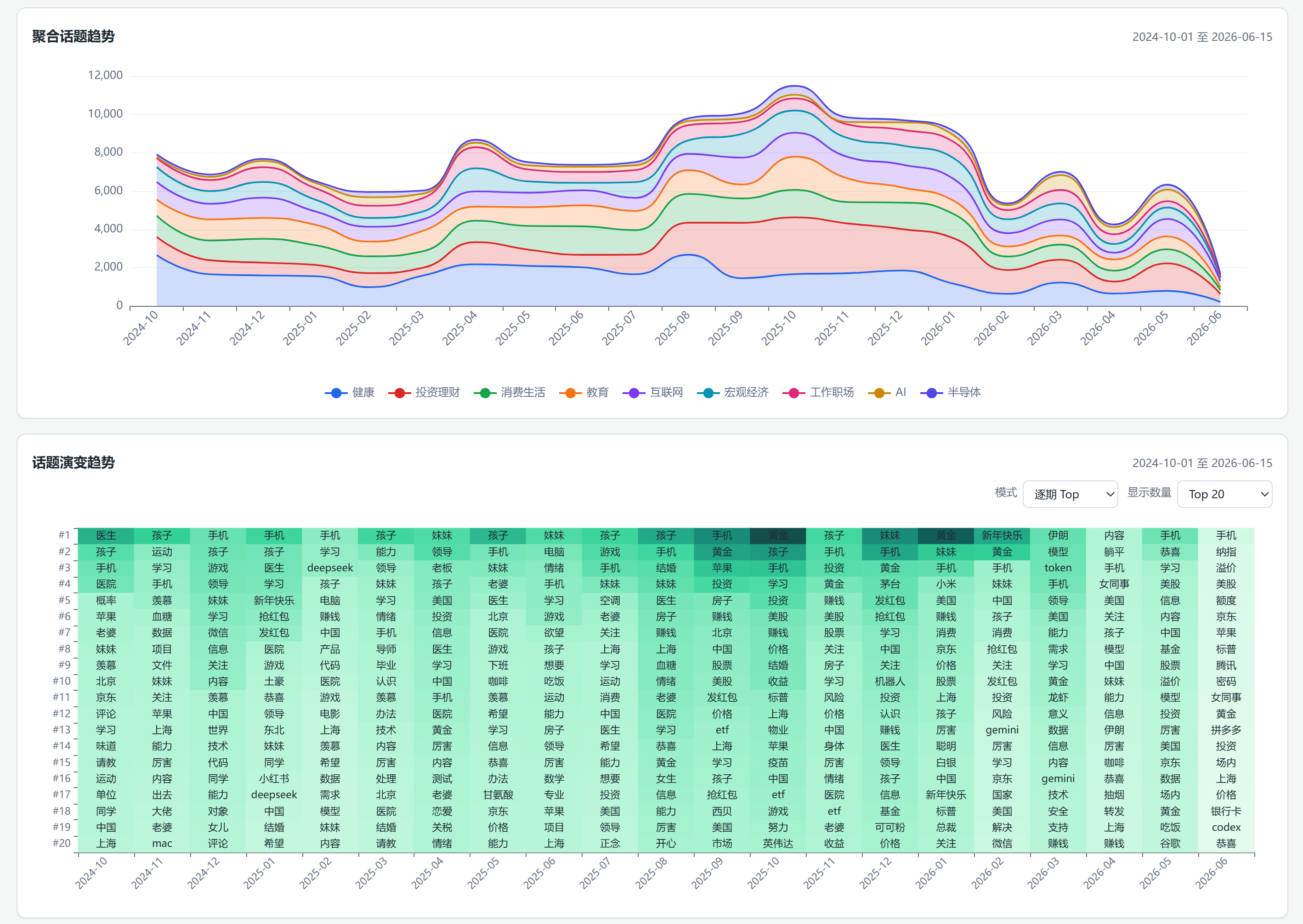
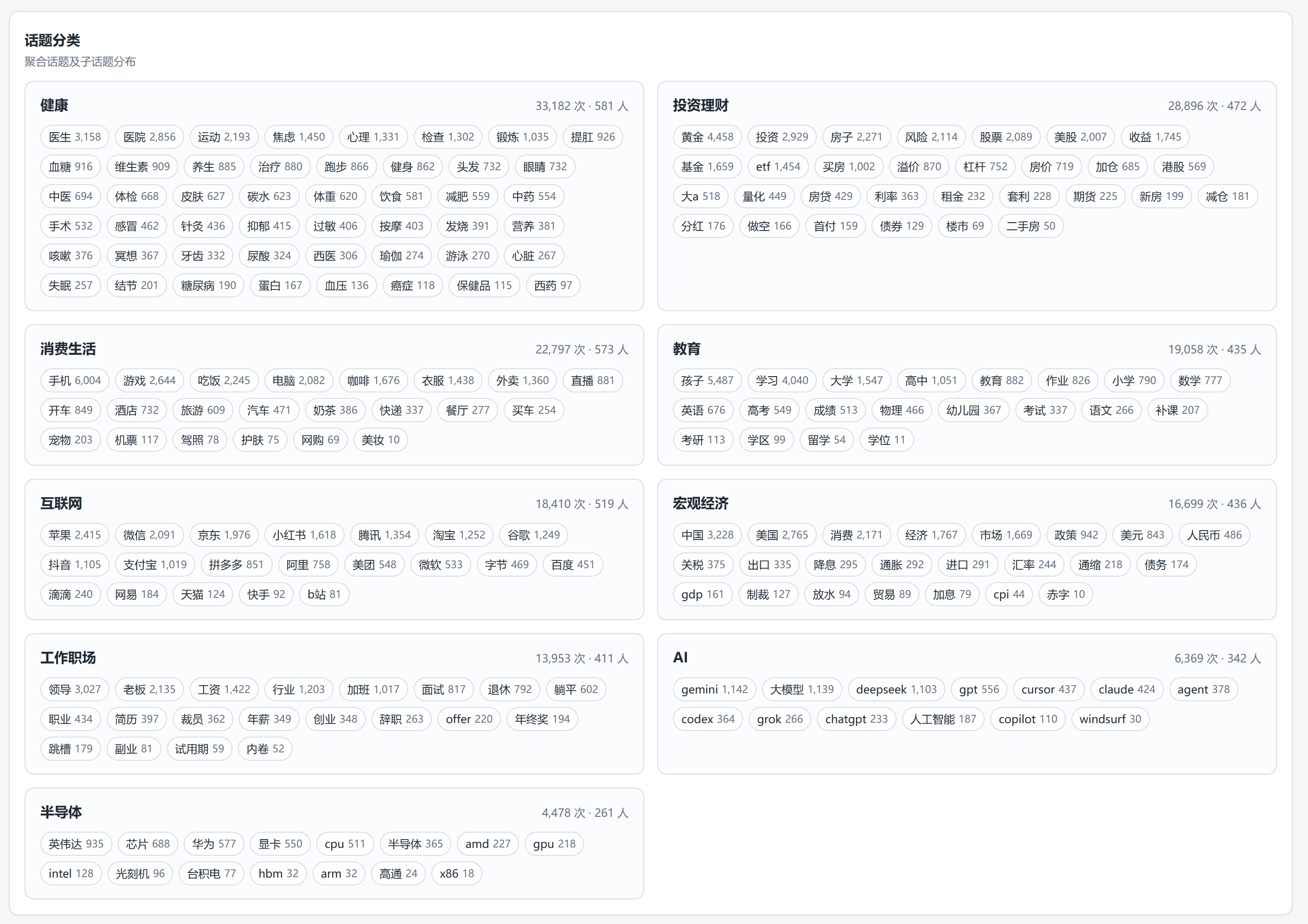
目前主要分析了活跃话题以及话题演变趋势(单个话题及聚合话题),其实可以做的点和挖掘的点还挺多,还在持续迭代优化中。
项目效果图如下。
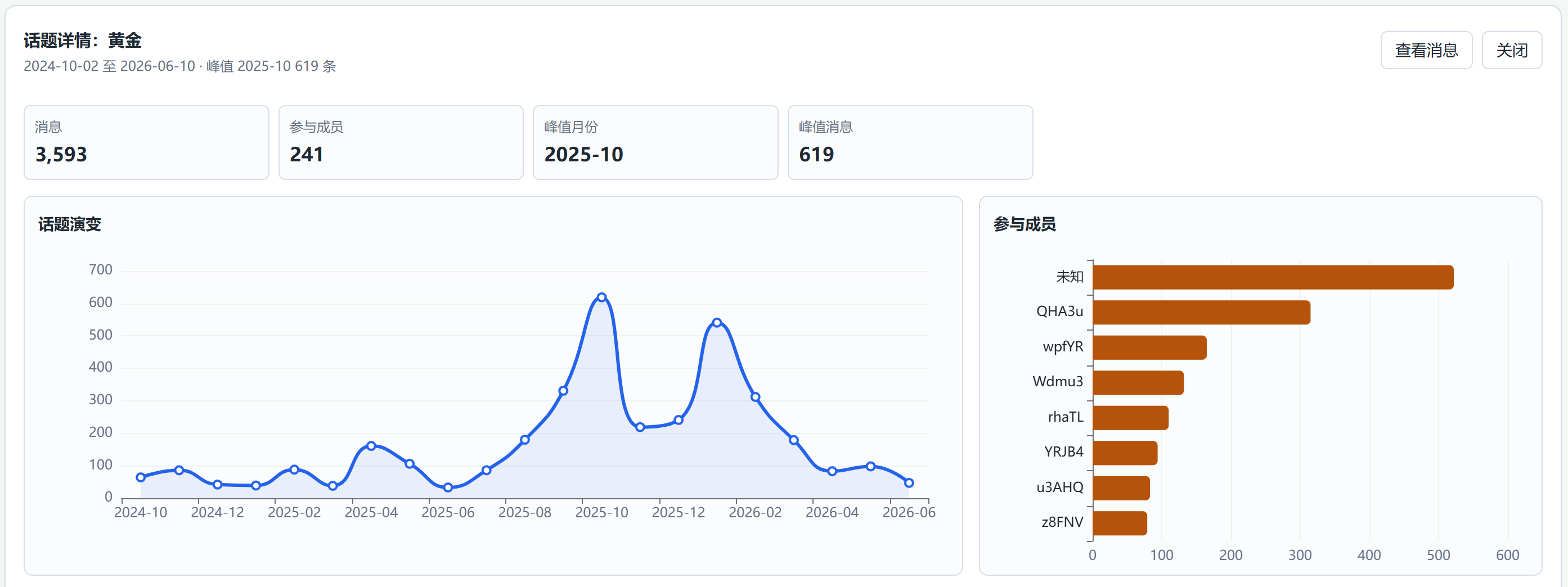
(1)、话题详情,其中参与成员已匿名化处理
(2)、话题演变趋势
(3)、聚合话题分布
(4)、简单成员画像
三、总结
1、大模型和 Agent 属于先进生产力,要积极拥抱,了解其基本原理并熟练掌握使用(上层工具变化很快,主要关注底层知识),且尽可能使用能力范围内能用到的最强的大模型,毕竟模型差点,人就要多做一点,实际上多做的可能远远不止一点:);
2、大模型不是万能的,存在其固有的局限性(如幻觉、不一致性等,本质概率),它属于工具,最终应该由人完成决策并对结果负责(在实际生产项目中,敬畏每一行代码);
3、大模型的上限或者说能发挥的最大价值,取决于它的使用者,如果使用者自身能力越强,那么能发挥它的作用/价值就越大。所以要注意自我水平的提升,持续学习;
4、国内使用国外的先进大模型同时存在内外两方面的限制(“混合双打”),目前通过 Claude Code 配置 Deep
5、大模型的一点使用经验分享:
- 问题描述尽可能清晰、准确,上下文信息给足(如有示例也可提供)。磨刀不误砍柴工,问题越清晰,回答越精准。提示词工程也是一门学问。”Talk is cheap. Show me the code.” vs. “Code is cheap. Show me the talk.”;
-
设定好目标及测试用例,做好约束,每次修改后都要跑测试并检查是否满足约束。结果做到可验证,可自行设计测试方法;
-
描述想法后,可以先让大模型进行评估并给出建议,再考虑编码实现;
-
优化系统时,可以让大模型从专业的角度评估整个系统,并给出优化建议,包括技术架构、界面设计与交互、性能等方面;
-
处理确定性任务时,尽可能让大模型设计好自动化程序,并且对每个关键步骤进行检测,在实践中迭代优化自动化程序;
-
多个大模型一起使用,交叉评估、优化、验证。且可以考虑让能力显贵较强的模型负责分析与规划(思考/推理),能力较弱的模型负责执行与验证。
6、大模型还在持续迭代变强,有幸见证它的发展。
另外,关于未来的发展,一个基础的想法是大模型+Agent+Host(
四、参考
1、Claude Code Docs(Claude 官方文档)
2、AI工程-大模型应用开发实战(书籍)
3、从零构建大模型(书籍)
7、AI Agent Performance Leaderboard(排行榜)
8、Artificial Analysis Intelligence Index(排行榜)
9、零废话!一文讲透从0构建AI Agent(简单科普)