阅读笔记主要来自《操作系统导论》第 28 章。该章对锁的基本思想以及锁的一系列实现等进行了系统性的介绍,可以帮助读者更好地了解锁的发展脉络及背后的原理。
1、为什么需要锁
举个例子,比如对于下面这句代码:
counter = counter + 1;
编译器所产生的代码序列(通过 objdump -h 反汇编查看)实际上是:
mov 0x0(%rip), %eax
add $0x1, %eax
mov %eax, 0x0(%rip)
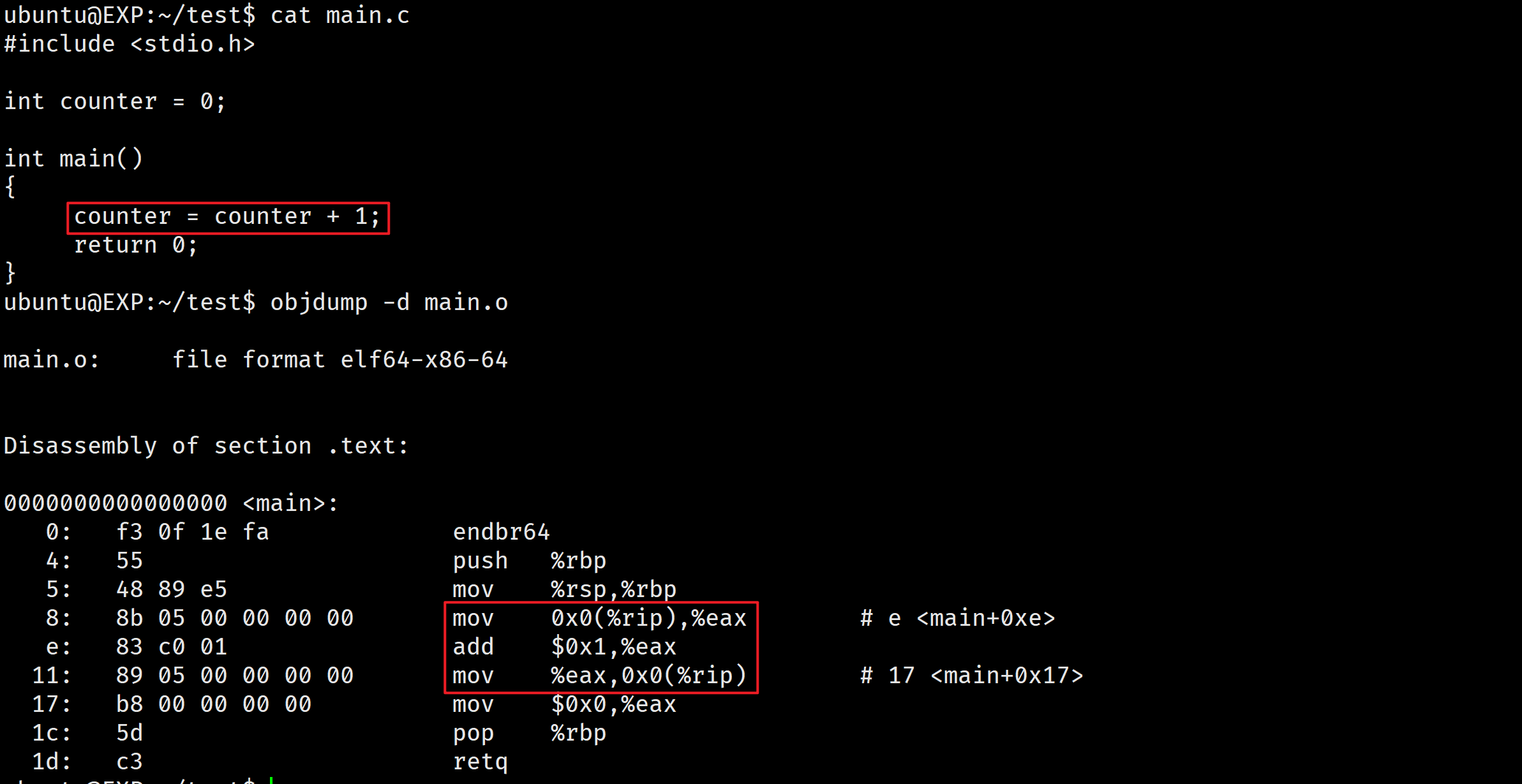
在这 3 条指令中,先用 x86 的 mov 指令,从内存地址处取出值,放入 eax。然后,给 eax 寄存器的值加 1(0x1)。最后,eax 的值被存回内存中相同的地址。
假设 counter 初始化为 50(地址为 0x8049a1c),当两个线程同时执行上述代码时,可能的情况为:
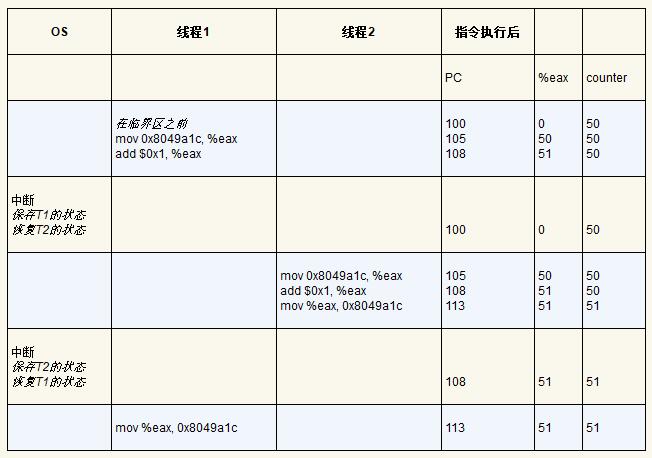
因此,最后变量 counter 的值可能是 51,而不是我们预期的 52(当然也有可能是 52)。
上述情况称为竞态条件(race condition),其结果取决于代码的实际执行时间,由于执行过程中发生的上下文切换,我们得到了错误的结果,事实上,可能每次都会得到不同的结果。
由于执行这段代码的多个线程可能导致竞争状态,因此我们将此段代码称为临界区(critical section)。临界区是访问共享变量(或更一般地说,共享资源)的代码片段,一定不能由多个线程同时执行。
我们真正想要的代码就是所谓的互斥(mutual exclusion)。这个属性保证了如果一个线程在临界区内执行,其他线程将被阻止进入临界区。
解决这个问题的一种途径是拥有更强大的指令,单步就能完成要做的事,从而消除不合时宜的中断的可能性。假设这条指令将一个值添加到内存位置,并且硬件保证它以原子方式(atomically)执行。当指令执行时,它会像期望那样执行更新。它不能在指令中间中断,因为这正是我们从硬件获得的保证:发生中断时,指令根本没有运行,或者运行完成,没有中间状态。
在这里,原子方式的意思是“作为一个单元”,有时我们说“全部或没有”。我们希望以原子方式执行编译器为 1 行代码所产生的 3 个指令序列。
因此,我们要做的是要求硬件提供一些有用的指令,可以在这些指令上构建一个通用的集合,即所谓的同步原语(synchronization primitive)。通过使用这些硬件同步原语,加上操作系统的一些帮助,我们将能够构建多线程代码,以同步和受控的方式访问临界区,从而可靠地产生正确的结果—— 尽管有并发执行的挑战。
现在,我们来回答为什么需要锁:
并发编程的一个最基本问题:希望原子式执行一系列指令,但由于单处理器上的中断(或者多个线程在多处理器上并发执行),难以直接实现。因此引入了锁来解决这一问题。程序员在代码中加锁,放在临界区周围,保证临界区可以像单条原子指令一样执行。
2、锁的基本思想
假设有一个用于更新共享变量的临界区,如下所示:
counter = counter + 1;
为了使用锁,我们给临界区增加了这样一些代码:
lock_t mutex; // some globally-allocated lock 'mutex'
...
lock(&mutex);
balance = balance + 1;
unlock(&mutex);
锁就是一个变量,因此我们需要声明一个某种类型的锁变量(如上面的 mutex)才能使用。这个锁变量(简称锁)保存了锁在某一时刻的状态。它要么是可用的(available,或 unlocked,或 free),表示没有线程持有锁,要么是被占用的(acquired,或 locked,或 held),表示有一个线程持有锁,正处于临界区。我们也可以保存其他的信息,比如持有锁的线程,或请求获取锁的线程队列,但这些信息会隐藏起来,锁的使用者不会发现。
lock() 和 unlock() 函数的语义很简单。调用 lock() 尝试获取锁,如果没有其他线程持有锁(即它是可用的),该线程会获得锁,进入临界区。这个线程有时被称为锁的持有者(owner)。如果另外一个线程对相同的锁变量(本例中的 mutex)调用lock(),因为锁被另一线程持有,该调用不会返回。这样,当持有锁的线程在临界区时,其他线程就无法进入临界区。
的持有者一旦调用 unlock(),锁就变成可用了。如果没有其他等待线程(即没有其他线程调用过lock() 并卡在那里),锁的状态就变成可用了。如果有等待线程(卡在lock()里),其中一个会(最终)注意到(或收到通知)锁状态的变化,获取该锁,进入临界区。
锁为程序员提供了最小程度的调度控制。我们把线程视为程序员创建的实体,但是被操作系统调度,具体方式由操作系统选择。锁让程序员获得一些控制权。通过给临界区加锁,可以保证临界区内只有一个线程活跃。锁将原本由操作系统调度的混乱状态变得更为可控。
POSIX 库将锁称为互斥量(mutex),因为它被用来提供线程之间的互斥。
POSIX 的 lock 和 unlock 函数会传入一个锁变量,因为我们可能用不同的锁来保护不同的变量。这样可以增加并发:不同于任何临界区都使用同一个大锁(粗粒度的锁策略),通常大家会用不同的锁保护不同的数据和结构,从而允许更多的线程进入临界区(细粒度的方案)。
3、实现一个锁
们已经从程序员的角度,对锁如何工作有了一定的理解。那如何实现一个锁呢?我们需要什么硬件支持?需要什么操作系统的支持?
3.1、评价锁
在实现锁之前,我们应该首先明确目标,因此我们要问,如何评价一种锁实现的效果。为了评价锁是否能工作以及是否工作得好,我们应该先设立一些标准。
第一是锁是否能完成它的基本任务,即提供互斥。最基本的,锁是否有效,能够阻止多个线程进入临界区?
第二是公平性。当锁可用时,是否每一个竞争线程有公平的机会抢到锁?用另一个方式来看这个问题是检查更极端的情况:是否有竞争锁的线程会饿死,一直无法获得锁?
最后是性能,具体来说,是使用锁之后增加的时间开销。有几种场景需要考虑。一种是没有竞争的情况,即只有一个线程抢锁、释放锁的开支如何?另外一种是一个CPU上多个线程竞争,性能如何?最后一种是多个CPU、多个线程竞争时的性能。通过比较不同的场景,我们能够更好地理解不同的锁技术对性能的影响。
3.2、控制中断实现
最早提供的互斥解决方案之一,就是在临界区关闭中断。这个解决方案是为单处理器系统开发的。代码如下:
void lock() {
DisableInterrupts();
}
void unlock() {
EnableInterrupts();
}
假设我们运行在这样一个单处理器系统上。通过在进入临界区之前关闭中断(使用特殊的硬件指令),可以保证临界区的代码不会被中断,从而原子地执行。结束之后,我们重新打开中断(同样通过硬件指令),程序正常运行。
这个方法的主要优点就是简单。显然不需要费力思考就能弄清楚它为什么能工作。没有中断,线程可以确信它的代码会继续执行下去,不会被其他线程干扰。遗憾的是,缺点很多。
首先,这种方法要求我们允许所有调用线程执行特权操作(打开关闭中断),即信任这种机制不会被滥用。众所周知,如果我们必须信任任意一个程序,可能就有麻烦了。比如一个贪婪的程序可能在它开始时就调用 lock(),从而独占处理器。更糟的情况是,恶意程序调用 lock() 后,一直死循环。后一种情况,系统无法重新获得控制,只能重启系统。关闭中断对应用要求太多,不太适合作为通用的同步解决方案。
第二,这种方案不支持多处理器。如果多个线程运行在不同的 CPU 上,每个线程都试图进入同一个临界区,关闭中断也没有作用。线程可以运行在其他处理器上,因此能够进入临界区。多处理器已经很普遍了,我们的通用解决方案需要更好一些。
第三,关闭中断导致中断丢失,可能会导致严重的系统问题。假如磁盘设备完成了读取请求,但CPU 错失了这一事实,那么,操作系统如何知道去唤醒等待读取的进程?
最后一个不太重要的原因就是效率低。与正常指令执行相比,现代 CPU 对于关闭和打开中断的代码执行得较慢。
基于以上原因,只在很有限的情况下用关闭中断来实现互斥原语。例如,在某些情况下操作系统本身会采用屏蔽中断的方式,保证访问自己数据结构的原子性,或至少避免某些复杂的中断处理情况。这种用法是可行的,因为在操作系统内部不存在信任问题,它总是信任自己可以执行特权操作。
一段时间以来,出于某种原因,大家都热衷于研究不依赖硬件支持的锁机制。后来这些工作都没有太多意义,因为只需要很少的硬件支持,实现锁就会容易很多(实际在多处理器的早期,就有这些硬件支持)。而且上面提到的方法无法运行在现代硬件(因为松散内存一致性模型),导致它们更加没有用处。
3.3、“简单实现”
因为关闭中断的方法无法工作在多处理器上,所以系统设计者开始让硬件支持锁。
最简单的硬件支持是测试并设置指令(test-and-set instruction),也叫作原子交换(atomic exchange)。为了理解 test-and-set 如何工作,我们首先实现一个不依赖它的锁,用一个变量标记锁是否被持有。
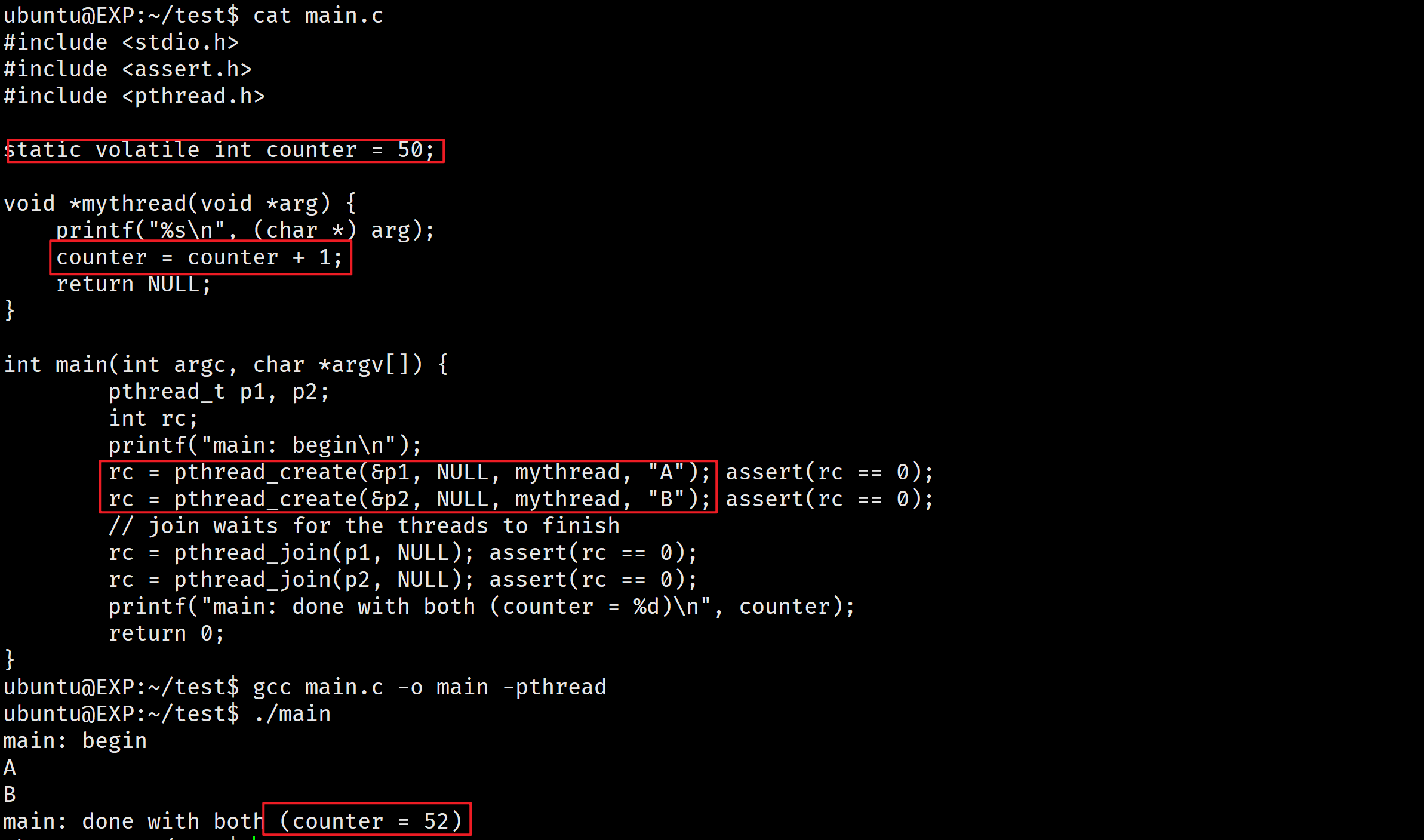
在第一次尝试中,想法很简单:用一个变量来标志锁是否被某些线程占用。第一个线程进入临界区,调用 lock(),检查标志是否为 1,为 1 时循环等待,否则往下执行,设置标志为 1,表明线程持有该锁。结束临界区时,线程调用 unlock(),清除标志,表示锁未被持有(已被释放)。
// 第一次尝试:简单标志
typedef struct lock_t { int flag; } lock_t;
void init(lock_t *mutex) {
// 0 -> lock is available, 1 -> held
mutex->flag = 0;
}
void lock(lock_t *mutex) {
while (mutex->flag == 1) // TEST the flag
; // spin-wait (do nothing)
mutex->flag = 1; // now SET it!
}
void unlock(lock_t *mutex) {
mutex->flag = 0;
}
当第一个线程正处于临界区时,如果另一个线程调用 lock(),它会在 while 循环中自旋等待(spin-wait),直到第一个线程调用 unlock() 清空标志。然后等待的线程会退出while循环,设置标志,执行临界区代码。
遗憾的是,这段代码有两个问题:正确性和性能。这个正确性问题在并发编程中很常见。假设代码按照下表执行,开始时 flag = 0。

从这种交替执行可以看出,通过适时的(不合时宜的)中断,我们很容易构造出两个线程都将标志设置为 1,都能进入临界区的场景。这种行为就是专家所说的“不好”,我们显然没有满足最基本的要求:互斥。
性能问题主要是线程在等待已经被持有的锁时,采用了自旋等待(spin-waiting)的技术,就是不停地检查标志的值。自旋等待在等待其他线程释放锁的时候会浪费时间。尤其是在单处理器上,一个等待 线程等待 的目标线程甚至无法运行(至少在上下文切换之前)。我们要开发出更成熟的解决方案,也应该考虑避免这种浪费。
3.4、测试并设置指令(原子交换)
尽管上面例子的想法很好,但没有硬件的支持是无法实现的。幸运的是,一些系统提供了这一指令,支持基于这种概念创建简单的锁。在 SPARC 上,这个指令叫 ldstub(load/store unsigned byte,加载/保存无符号字节);在 x86 上,是 xchg(atomic exchange,原子交换)指令。通常也称为测试并设置指令(test-and-set)。
我们用下面的 C 代码片段来观察测试并设置指令做了什么:
int TestAndSet(int *old_ptr, int new) {
int old = *old_ptr; // fetch old value at old_ptr
*old_ptr = new; // store 'new' into old_ptr
return old; // return the old value
}
测试并设置指令做了下述事情。它返回 old_ptr 指向的旧值,同时更新为 new 的新值。当然,关键是这些代码是原子地执行。因为既可以测试旧值,又可以设置新值,所以我们把这条指令叫作“测试并设置”。这一条指令完全可以实现一个简单的自旋锁(spin lock),代码如下所示。
// 利用 test-and-set 的简单自旋锁
typedef struct lock_t {
int flag;
} lock_t;
void init(lock_t *lock) {
// 0 indicates that lock is available, 1 that it is held
lock->flag = 0;
}
void lock(lock_t *lock) {
while (TestAndSet(&lock->flag, 1) == 1)
; // spin-wait (do nothing)
}
void unlock(lock_t *lock) {
lock->flag = 0;
}
我们来确保理解为什么这个锁能工作。首先假设一个线程在运行,调用 lock(),没有其他线程持有锁,所以 flag 是 0。当调用 TestAndSet(flag, 1) 方法,返回 0,线程会跳出 while 循环,获取锁。同时也会原子的设置 flag 为 1,标志锁已经被持有。当线程离开临界区,调用 unlock() 将 flag 清理为0。
第二种场景是,当某一个线程已经持有锁(即 flag 为 1)。本线程调用 lock(),然后调用TestAndSet(flag, 1),这一次返回 1。只要另一个线程一直持有锁,TestAndSet() 会重复返回 1,本线程会一直自旋。当 flag 终于被改为 0,本线程会调用 TestAndSet(),返回 0 并且原子地设置为 1,从而获得锁,进入临界区。
将测试(test 旧的锁值)和设置(set 新的值)合并为一个原子操作之后,我们保证了只有一个线程能获取锁。这就实现了一个有效的互斥原语!
现在理解了为什么这种锁被称为自旋锁(spin lock)。这是最简单的一种锁,一直自旋,利用 CPU周期,直到锁可用。在单处理器上,需要抢占式的调度器(preemptive scheduler,即不断通过时钟中断一个线程,运行其他线程)。否则,自旋锁在单 CPU 上无法使用,因为一个自旋的线程永远不会放弃 CPU。
现在可以按照之前的标准来评价基本的自旋锁了。锁最重要的一点是正确性:能够互斥吗?答案是可以的:自旋锁一次只允许一个线程进入临界区。因此,这是正确的锁。
下一个标准是公平性。自旋锁对于等待线程的公平性如何呢?能够保证一个等待线程会进入临界区吗?答案是自旋锁不提供任何公平性保证。实际上,自旋的线程在竞争条件下可能会永远自旋。自旋锁没有公平性,可能会导致饿死。
最后一个标准是性能。使用自旋锁的成本是多少?为了更小心地分析,我们建议考虑几种不同的情况。首先,考虑线程在单处理器上竞争锁的情况。然后,考虑这些线程跨多个处理器。
- 对于自旋锁,在单 CPU 的情况下,性能开销相当大。假设一个线程持有锁进入临界区时被抢占。调度器可能会运行其他每一个线程(假设有 N−1 个这种线程)。而其他线程都在竞争锁,都会在放弃 CPU 之前,自旋一个时间片,浪费 CPU 周期。
- 但是,在多 CPU 上,自旋锁性能不错(如果线程数大致等于 CPU 数)。假设线程 A 在 CPU 1,线程 B 在 CPU 2 竞争同一个锁。线程 A(CPU 1)占有锁时,线程 B 竞争锁就会自旋(在CPU 2上)。然而,临界区一般都很短,因此很快锁就可用,然后线程 B 获得锁。自旋等待其他处理器上的锁,并没有浪费很多CPU周期,因此效果不错。
3.5、比较并交换指令
某些系统提供了另一个硬件原语,即比较并交换指令(SPARC 系统中是 compare-and-swap,x86 系统是 compare-and-exchange)。该指令的 C 语言伪代码如下:
int CompareAndSwap(int *ptr, int expected, int new) {
int actual = *ptr;
if (actual == expected)
*ptr = new;
return actual;
}
比较并交换的基本思路是检测 ptr 指向的值是否和 expected 相等;如果是,更新 ptr 所指的值为新值。否则,什么也不做。不论哪种情况,都返回该内存地址的实际值,让调用者能够知道执行是否成功。
有了比较并交换指令,就可以实现一个锁,类似于用测试并设置那样。例如,我们只要用下面的代码替换 lock() 函数:
void lock(lock_t *lock) {
while (CompareAndSwap(&lock->flag, 0, 1) == 1)
; // spin
}
其余代码和上面测试并设置的例子完全一样。代码工作的方式很类似,检查标志是否为 0,如果是,原子地交换为 1,从而获得锁。锁被持有时,竞争锁的线程会自旋。
对于如何创建 C 可调用的 x86 版本的比较并交换,可以参考下面的代码:
char CompareAndSwap(int *ptr, int old, int new) {
unsigned char ret;
// Note that sete sets a 'byte' not the word
__asm__ __volatile__ (
" lock\n"
" cmpxchgl %2,%1\n"
" sete %0\n"
: "=q" (ret), "=m" (*ptr)
: "r" (new), "m" (*ptr), "a" (old)
: "memory");
return ret;
}
3.6、链接的加载和条件式存储指令
一些平台提供了实现临界区的一对指令。例如 MIPS架构 中,链接的加载(load-linked)和条件式存储(store-conditional)可以用来配合使用,以实现其他并发结构。其 C 语言伪代码如下所示。
int LoadLinked(int *ptr) {
return *ptr;
}
int StoreConditional(int *ptr, int value) {
if (no one has updated *ptr since the LoadLinked to this address) {
*ptr = value;
return 1; // success!
} else {
return 0; // failed to update
}
}
链接的加载指令和典型加载指令类似,都是从内存中取出值存入一个寄存器。关键区别来自条件式存储指令,只有上一次加载的地址在期间都没有更新时,才会成功(同时更新刚才链接的加载的地址的值)。成功时,条件存储返回 1,并将 ptr 指的值更新为 value。失败时,返回 0,并且不会更新值。
用该指令实现锁的代码如下所示。
void lock(lock_t *lock) {
while (1) {
while (LoadLinked(&lock->flag) == 1)
; // spin until it's zero
if (StoreConditional(&lock->flag, 1) == 1)
return; // if set-it-to-1 was a success: all done
// otherwise: try it all over again
}
}
void unlock(lock_t *lock) {
lock->flag = 0;
}
// lock 更简洁的实现
void lock(lock_t *lock) {
while (LoadLinked(&lock->flag) || !StoreConditional(&lock->flag, 1))
; // spin
}
首先,一个线程自旋等待标志被设置为 0(因此表明锁没有被保持)。一旦如此,线程尝试通过条件存储获取锁。如果成功,则线程自动将标志值更改为 1,从而可以进入临界区。
请注意条件式存储失败是如何发生的。一个线程调用lock(),执行了链接的加载指令,返回0。在执行条件式存储之前,中断产生了,另一个线程进入lock的代码,也执行链接式加载指令,同样返回0。现在,两个线程都执行了链接式加载指令,将要执行条件存储。重点是只有一个线程能够成功更新标志为1,从而获得锁;第二个执行条件存储的线程会失败(因为另一个线程已经成功执行了条件更新),必须重新尝试获取锁。
3.7、获取并增加指令
最后一个硬件原语是获取并增加(fetch-and-add)指令,它能原子地返回特定地址的旧值,并且让该值自增一。获取并增加的 C 语言伪代码如下:
int FetchAndAdd(int *ptr) {
int old = *ptr;
*ptr = old + 1;
return old;
}
在这个例子中,我们会用获取并增加指令实现一个更有趣的 ticke t锁,这是Mellor-Crummey和Michael Scott 提出的。 lock 和 unlock 的代码如下所示。
typedef struct lock_t {
int ticket;
int turn;
} lock_t;
void lock_init(lock_t *lock) {
lock->ticket = 0;
lock->turn = 0;
}
void lock(lock_t *lock) {
int myturn = FetchAndAdd(&lock->ticket);
while (lock->turn != myturn)
; // spin
}
void unlock(lock_t *lock) {
FetchAndAdd(&lock->turn);
}
不是用一个值,这个解决方案使用了ticket和turn变量来构建锁。基本操作也很简单:如果线程希望获取锁,首先对一个 ticket 值执行一个原子的获取并相加指令。这个值作为该线程的 “turn”(顺位,即 myturn)。根据全局共享的 lock->turn 变量,当某一个线程的(myturn == turn)时,则轮到这个线程进入临界区。unlock 则是增加 turn,从而下一个等待线程可以进入临界区。
不同于之前的方法:本方法能够保证所有线程都能抢到锁。只要一个线程获得了 ticket 值,它最终会被调度。之前的方法则不会保证。比如基于测试并设置的方法,一个线程有可能一直自旋,即使其他线程在获取和释放锁。
相当于先取号然后再排队等号...
3.8、自旋过多如何处理
基于硬件的锁简单(只有几行代码)而且有效,这也是任何好的系统或者代码的特点。但是,某些场景下,这些解决方案会效率低下。
以两个线程运行在单处理器上为例,当一个线程(线程 0)持有锁时,被中断。第二个线程(线程 1)去获取锁,发现锁已经被持有。因此,它就开始自旋。接着自旋。然后它继续自旋。最后,时钟中断产生,线程 0 重新运行,它释放锁。最后(比如下次它运行时),线程1不需要继续自旋了,它获取了锁。因此,类似的场景下,一个线程会一直自旋检查一个不会改变的值,浪费掉整个时间片!
如果有 N 个线程去竞争一个锁,情况会更糟糕。同样的场景下,会浪费 N−1 个时间片,只是自旋并等待一个线程释放该锁。因此,我们的下一个问题是:如何让锁不会不必要地自旋,以避免浪费 CPU 时间。
硬件支持让我们有了很大的进展:我们已经实现了有效、公平(通过 ticket 锁)的锁。但是,问题仍然存在:如果临界区的线程发生上下文切换,其他线程只能一直自旋,等待被中断的(持有锁的)进程重新运行。有什么好办法?
第一种简单友好的方法就是,在要自旋的时候,放弃 CPU。
void lock(lock_t *lock) {
int myturn = FetchAndAdd(&lock->ticket);
while (lock->turn != myturn)
yield(); // give up the CPU
}
在这种方法中,我们假定操作系统提供原语 yield(),线程可以调用它主动放弃 CPU,让其他线程运行。线程可以处于 3 种状态之一(运行、就绪和阻塞)。yield() 系统调用能够让运行态变为就绪态,从而允许其他线程运行。因此,让出线程本质上取消调度了它自己。
考虑在单 CPU 上运行两个线程。在这个例子中,基于 yield 的方法十分有效。一个线程调用 lock(),发现锁被占用时,让出 CPU,另外一个线程运行,完成临界区。在这个简单的例子中,让出方法工作得非常好。
现在来考虑许多线程(例如 100 个)反复竞争一把锁的情况。在这种情况下,一个线程持有锁,在释放锁之前被抢占,其他 99 个线程分别调用 lock(),发现锁被抢占,然后让出 CPU。假定采用某种轮转调度程序,这 99 个线程会一直处于运行—让出这种模式,直到持有锁的线程再次运行。虽然比原来的浪费 99 个时间片的自旋方案要好,但这种方法仍然成本很高,上下文切换的成本是实实在在的,因此浪费很大。
更糟的是,我们还没有考虑饿死的问题。一个线程可能一直处于让出的循环,而其他线程反复进出临界区。很显然,我们需要一种方法来解决这个问题。
3.9、使用队列:休眠替代自旋
面一些方法的真正问题是存在太多的偶然性。调度程序决定如何调度。如果调度不合理,线程或者一直自旋(第一种方法),或者立刻让出 CPU(第二种方法)。无论哪种方法,都可能造成浪费,也不能防止饿死。
因此,我们必须显式地施加某种控制,决定锁释放时,谁能抢到锁。为了做到这一点,我们需要操作系统的更多支持,并需要一个队列来保存等待锁的线程。
简单起见,我们利用 Solaris 提供的支持,它提供了两个调用:park() 能够让调用线程休眠,unpark(threadID) 则会唤醒 threadID 标识的线程。可以用这两个调用来实现锁,让调用者在获取不到锁时睡眠,在锁可用时被唤醒。代码如下所示。
typedef struct lock_t {
int flag;
int guard;
queue_t *q;
} lock_t;
void lock_init(lock_t *m) {
m->flag = 0;
m->guard = 0;
queue_init(m->q);
}
void lock(lock_t *m) {
while (TestAndSet(&m->guard, 1) == 1)
; //acquire guard lock by spinning
if (m->flag == 0) {
m->flag = 1; // lock is acquired
m->guard = 0;
} else {
queue_add(m->q, gettid());
m->guard = 0;
park();
}
}
void unlock(lock_t *m) {
while (TestAndSet(&m->guard, 1) == 1)
; //acquire guard lock by spinning
if (queue_empty(m->q))
m->flag = 0; // let go of lock; no one wants it
else
unpark(queue_remove(m->q)); // hold lock (for next thread!)
m->guard = 0;
}
在这个例子中,我们做了两件有趣的事。首先,我们将之前的测试并设置和等待队列结合,实现了一个更高性能的锁。其次,我们通过队列来控制谁会获得锁,避免饿死。
至于条件变量和信号量呢?
第一点, guard 基本上起到了自旋锁的作用,围绕着 flag 和队列操作。因此,这个方法并没有完全避免自旋等待。线程在获取锁或者释放锁时可能被中断,从而导致其他线程自旋等待。但是,这个自旋等待时间是很有限的(不是用户定义的临界区,只是在 lock 和 unlock 代码中的几个指令),因此,这种方法也许是合理的。
第二点,在 lock() 函数中,如果线程不能获取锁(它已被持有),线程会把自己加入队列(通过调用 gettid() 获得当前的线程 ID),将 guard 设置为 0,然后让出 CPU。
第三点,当要唤醒另一个线程时,flag 并没有设置为 0。为什么呢?其实这不是错,而是必须的!线程被唤醒时,就像是从 park() 调用返回。但是,此时它没有持有 guard,所以也不能将 flag 设置为 1。因此,我们就直接把锁从释放的线程传递给下一个获得锁的线程,期间 flag 不必设置为 0。
最后,注意解决方案中的竞争条件,就在 park() 调用之前。如果不凑巧,一个线程将要 park 时,这时切换到另一个线程(比如持有锁的线程),这可能会导致麻烦。比如,如果该线程随后释放了锁。接下来第一个线程的 park 会永远睡下去(可能)。这种问题有时称为唤醒 / 等待竞争(wakeup/waiting race)。为了避免这种情况,我们需要额外的工作。
Solaris 通过增加了第三个系统调用 separk() 来解决这一问题。通过 setpark(),一个线程表明自己马上要 park。如果刚好另一个线程被调度,并且调用了 unpark,那么后续的 park 调用就会直接返回,而不是一直睡眠。
queue_add(m->q, gettid());
m->guard = 0; // new code
park();
另外一种方案就是将guard传入内核。在这种情况下,内核能够采取预防措施,保证原子地释放锁,把运行线程移出队列。
以上的方法展示了如今真实的锁是如何实现的:一些硬件支持(更加强大的指令)和一些操作系统支持(例如 Solaris的 park() 和 unpark() 原语)。当然,细节有所不同,执行这些锁操作的代码通常是高度优化的。
4、总结
首先,为什么需要锁,其实就是为了能够原子式执行一系列指令。
其次,对于锁本身而言,就是一个变量,执行临界区代码前加锁,以防止其他线程进入临界区;执行完代码后解锁,以让其他线程进入临界区。
最后,对于锁的实现。应当先确定衡量指标:有效性、公平性以及高效性。至于具体实现,还是需要硬件和操作系统的配合。毕竟自己写的系列指令无法脱离系统/硬件时无法原子式地执行。
- 对于 test and set,其实就是在 lock 为 0 时可以获得锁,并在获得锁后把 lock 置 1,从而让其他线程无法获得锁
- 对于 compare and swap,本质和 test and set 是一样地,但是功能更加强大,因为比较和设置的值均可自定义。且判断 lock 已经为 1 时,就不用再设置 lock 为 1 了(test and set 没有判断直接设为 1)
- 对于 load-linked 以及 store-conditional,其实也就是判断 lock 是否被更新过,也就是是否已经被其他线程获取
- 对于 fetch and set,类似先取号再排队,到号了的时候再获取锁,可以在一定程度上实现公平性
- 上述所有指令都是自旋锁,也就是在获取锁时一直等待,但此时可以主动放弃等待,让 cpu 执行其他线程,但是这样在线程较多时还是有很大的上下文切换开销(获取锁-让出)。且还存在饿死的问题。【自旋锁也有应用场景:当等待的时间很短而上下文切换开销很大时,可以不必主动休眠】
- 为此,我们可以采用队列,将因无法获得锁而休眠的线程先保存到队列中,等到锁可用时再唤醒队列中休眠的线程。
- 最后的处理有些像锁+条件变量,或者信号量...



保罗
中国广东大佬现在发文章这么硬核了么,什么工作呀
太傅
中国湖南@保罗 过奖过奖,准备找偏底层的C/C++开发的工作。
淄博测漏
中国山东感谢分享,赞一个