不知道大家有没有这样一个疑问:当我们在C/C++的IDE上敲完一个程序的代码后,只需要点击编译运行按钮稍微等待几秒就可以生成一个可执行程序,那编译运行这个过程到底是怎样的呢?由.c/.cpp源文件如何得到.exe(Windows)可执行文件呢?
相信看完本文,你会有一个清晰的答案: )
简单来说,整个过程分为四个阶段:预处理(Pre-Processing)、编译(Compilation)、汇编(Assembling)、链接(Linking)。如下图所示(来自CSAPP一书)。

注意:其中源程序、修改了的源程序和汇编程序都是文本文件,而可重定位目标程序和可执行目标程序都是二进制文件。
似乎到这里就该结束了,因为整个过程已经讲完了?。当然如果只是这样介绍的话本文就没有存在的价值了,我们还得再深入一点分别讲解这四个阶段?。
预处理
首先我们准备一个简单的Hello World程序,命名为main.c。
#include <stdio.h>
#define info "Hello, world\n"
int main()
{
// A simple program.
printf(info);
return 0;
}
预处理阶段做的事情就是预处理器(cpp)根据以字符#开头的代码修改原始的C程序。
- 比如
#include <stdio.h>,将头文件stdio.h中的内容加到程序文本中 - 比如
#define info "Hello, world\n",会将宏定义的info替换成字符串"Hello, world\n"(当然我这里只是为了举例,一般我们不这么写) - 此外,会将注释比如
// A simple program.删除
预处理是直接对源文件进行处理(不关注语法规则), 然后得到另一个C程序,通常以.i作为文件扩展名。
我们可以在Linux系统(我这里用的是Ubuntu)下直接使用gcc -E main.c -o main.i命令得到预处理后的C程序main.i。我截取了一部分(总共有800+行),可以很明显的看到:引入了头文件,info被替换了,注释没了,还添加了一些特殊的标记,告诉编译器每行的来源,以便它可以使用它们来产生合理的错误消息。
# 1 "main.c"
# 1 "<built-in>"
# 1 "<command-line>"
# 31 "<command-line>"
# 1 "/usr/include/stdc-predef.h" 1 3 4
......
......
extern void funlockfile (FILE *__stream) __attribute__ ((__nothrow__ , __leaf__));
# 868 "/usr/include/stdio.h" 3 4
# 2 "main.c" 2
# 3 "main.c"
int main()
{
printf("Hello, world\n");
return 0;
}
编译
编译阶段做的事情就是编译器(cc1)将C程序main.i翻译成汇编语言程序main.s。
- 检查C程序的语法错误
- 将文件翻译成中间代码,即汇编语言
- 可选地优化翻译后的中间代码,获得更好的性能
我们可以使用gcc -S main.i -o main.s得到翻译后的汇编程序main.s,截取部分如下。
.file "main.c"
.text
.LC0:
.string "Hello, world"
.text
.globl main
main:
.LFB0:
.cfi_startproc
pushq %rbp
movq %rsp, %rbp
......
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu 7.3.0-27ubuntu1~18.04) 7.3.0"
.section .note.GNU-stack,"",@progbits
其中的语句比如pushq %rbp描述了一条低级机器语言指令。汇编语言是有用的,它为不同高级语言的不同汇编器提供了通用的输出语言,C汇编器和Fortran汇编器产生的输出文件都是一样的汇编语言。
汇编
汇编阶段做的事情就是汇编器(as)将main.s翻译成机器语言指令,把这些指令打包成一种叫做可重定位目标程序的格式,并将结果保存在目标文件main.o(Windows下为xx.obj而Linux下为xx.o)中。main.o是一个二进制文件,如果我们使用文本编辑器打开main.o,会看到一堆乱码。
我们可以使用gcc -c main.s -o main.o得到可重定位目标程序main.o,如下所示。
LF>?@@
UH䈍=距ello, worldGCC: (Ubuntu 7.3.0-27ubuntu1~18.04) 7.3.0zRx
#main.cmain_GLOBAL_OFFSET_TABLE_puts?ÿÿ C
?
?ÿÿ .symtab.strtab.shstrtab.rela.text.data.bss.rodata.comment.note.GNU-stack.rela.eh_frame @0 &90d+BWR@@
不出所料的一堆乱码?。
链接
我们的main.c程序中使用了printf函数,printf函数是每个C编译器都提供的标准C库中的一个函数,它存在于一个名为printf.o的单独预编译好了的目标文件中。
链接阶段做的事情就是链接器(ld)将需要用到的目标文件比如main.o和printf.o进行合并,并生成一个可执行(目标)文件,可以被加载到内存中,由系统执行。
实际上我们直接执行gcc main.c -o main命令得到的就是可执行文件,Windows下为.exe,Linux下默认为具有可执行权限的a.out,当然我们使用了-o来自定义输出文件名。

以上就是整个编译执行过程,看到这里你有没有明白了呢?。
By the way
顺便提一下,你知道编译型语言(C/C++)和解释性语言(Python/JAVA)的区别吗?
这里引用一下知乎某个匿名用户的回答,很有意思。
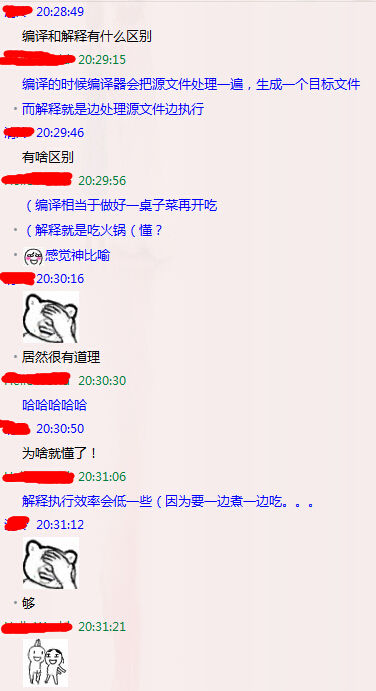
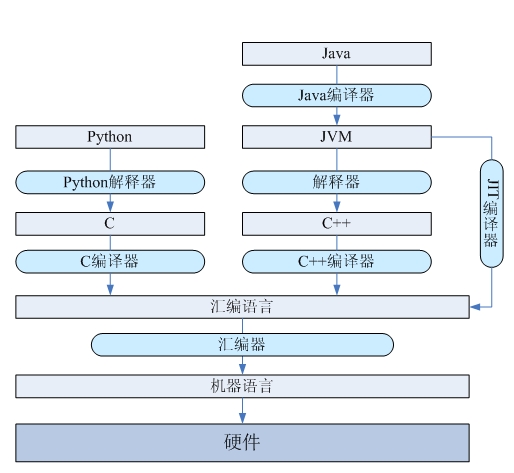
形象的解释就是这样,详细的解释可以参考卡图卢斯的博客:【Language】解释性语言和编译型语言的区别和不同和jack-zhu的博客:解释型语言和编译型语言的区别,下面也放一张图片。
By the way2
没想到吧,还有一个惊喜?。
关于Windows下.obj、.lib、.dll、.exe文件的关系和Linux下 .o、.a、.so文件的关系详细解释可以参考Oldpan的博客,讲的很清楚。
简单来说,.obj就是我们在汇编阶段得到的可重定位目标程序,.lib是静态链接库的库文件,.dll是动态链接库的库文件,.lib和.dll都是多个.obj文件的集合,其中.lib是程序编译时汇编阶段需要的,dll是.exe运行时需要调用的。
Linux下的.o对于Windows下的.obj,.a对应.lib,.so对应.dll。
参考资料
- 机械工业出版社,深入理解计算机系统(原书第3版)
- Stackoverflow,How does the compilation/linking process work?
- Codeforwin,The C compilation process
- Oldpan,浅析Linux中的.a、.so、和.o文件


Ryan Wang
中国上海我去,怎么突然换主题了,刚刚还在看。
太傅
中国广东@Ryan Wang 现在在启用新主题,真巧。